Os aplicativos da Web apresentam um conjunto complexo de questões de segurança para arquitetos, designers e desenvolvedores. Os aplicativos da Web mais seguros e resistentes a ataques são aqueles que foram criados com o requisito segurança em primeiro lugar.
Você deve aplicar práticas de arquitetura e design e incorporar considerações de implantação e diretivas de segurança corporativas durante as fases iniciais do projeto. Se isso não for feito, poderá resultar em aplicativos que não podem ser implantados numa infra–estrutura existente sem comprometer a segurança.
Este módulo apresenta um conjunto de diretrizes de segurança para projeto e arquitetura. Ele foi organizado por categoria de vulnerabilidade dos aplicativos comuns. São as áreas principais de segurança dos aplicativos da Web e são as mesmas onde os erros ocorrem com mais frequência.
Objetivos
Utilize este módulo para:
• Identificar as questões principais de projeto e arquitetura de aplicativos da Web seguros.
• Considerar as principais questões de implantação no momento do projeto.
• Projetar estratégias para melhorar a validação da entrada do aplicativo da Web.
• Criar mecanismos seguros de autenticação e gerenciamento de sessões.
• Escolher um modelo de autorização apropriado.
• Implementar práticas eficientes de gerenciamento de contas e proteger as sessões dos usuários.
• Utilizar criptografia para oferecer privacidade, não–recusa, proteção contra violações e autenticação.
• Evitar a manipulação de parâmetros.
• Criar estratégias de auditoria e log.
Aplicação
Embora contidas no livro sobre segurança ASP.NET, as informações deste módulo são importantes para qualquer pessoa interessada em desenvolver aplicativos da Web seguros.
Como utilizar este módulo
O foco deste módulo está nas diretrizes e nos princípios que você deve seguir ao projetar um aplicativo.
Para aproveitar ao máximo este módulo:
• Conheça as ameaças ao seu aplicativo para que você possa garantir que isso seja solucionado pelo seu projeto.
Leia, “Ameaças e Contramedidas”, para entender as ameaças a considerar. O módulo 2 relaciona as ameaças que podem prejudicar seu aplicativo. Considere essas ameaças durante a fase de projeto.
• Use uma abordagem sistemática para as áreas principais nas quais o aplicativo poderia ficar vulnerável a ataques. Pontos nos quais se concentrar: considerações sobre a implantação; validação da entrada; autenticação e autorização; criptografia e confidencialidade dos dados; gerenciamento de configuração, sessões e exceções e auditoria e log adequados para garantir a criação de contas.
Questões de arquitetura e projeto para aplicativos da Web
Os aplicativos da Web apresentam a designers e desenvolvedores muitos desafios. Como o protocolo HTTP não mantém um registro das sessões por usuário, o registro passa a ser de responsabilidade do aplicativo. Como precursor disso, o aplicativo deve ser capaz de identificar o usuário utilizando alguma forma de autenticação. Como todas as decisões subseqüentes de autorização baseiam–se na identidade do usuário, é essencial que o processo de autenticação seja seguro e que o mecanismo de tratamento da sessão utilizado para monitorar os usuários autenticados seja igualmente bem protegido. Projetar os mecanismos de autenticação seguros e o gerenciamento de sessão é apenas parte das questões com que se deparam designers e desenvolvedores de aplicativos da Web. Outros desafios surgem porque a entrada e a saída de dados são feitos por redes públicas. Impedir a manipulação de parâmetros e a divulgação de dados confidenciais é outra questão importante.
As diretrizes de projeto apresentadas neste módulo estão organizadas por categoria de vulnerabilidade do aplicativo. A experiência mostra que um projeto deficiente nessas áreas em particular cria vulnerabilidades de segurança.
Vulnerabilidades do aplicativo da Web e possíveis problemas causados por um projeto ruim
Categoria da vulnerabilidade e possível problema causado por um projeto ruim
Validação da entrada Ataques realizados incorporando–se sequências de caracteres mal–intencionadas em sequências de caracteres de consulta, campos de formulário, cookies e cabeçalhos HTTP. Eles incluem execução de comandos, ataques XSS (cross-site scripting), inclusão de código SQL e estouro de buffer.
Autenticação Spoofing de identidade, quebra de senha, elevação de privilégios e acesso não–autorizado.
Autorização Acesso a dados confidenciais ou restritos, violação e execução de operações não–autorizadas.
Gerenciamento de configuração Acesso não–autorizado a interfaces administrativas, capacidade de atualizar dados de configuração e acesso não–autorizado a contas de usuários e perfis de contas.
Dados confidenciais Informações confidenciais divulgadas e violação de dados.
Gerenciamento de sessão Captura de identificadores de sessão, resultando em sequestro de sessão e spoofing de identidade.
Criptografia Acesso a dados confidenciais, a credenciais de contas ou a ambos.
Manipulação de parâmetros Ataques de atravessamento de caminho, execução de comando e mecanismos para ignorar o controle de acesso, entre outros, levando à divulgação de informações ,elevação de privilégios e negação de serviço.
Gerenciamento de exceções Negação de serviço e divulgação de detalhes confidenciais do sistema.
Auditoria e log Falha ao indicar sinais de invasão, incapacidade de comprovar as ações de um usuário e dificuldades no diagnóstico de problemas.
Considerações para implantação
Durante a fase de design do aplicativo, analise as diretivas e os procedimentos da empresa junto a infra–estrutura na qual seu aplicativo será implantado. Freqüentemente, o ambiente de destino é rígido e o projeto do aplicativo deve refletir as restrições. Às vezes, são necessárias mudanças no projeto, por exemplo, devido a restrições de protocolo ou porta ou topologias de implantação específicas. Identifique as restrições no início da fase de projeto para evitar surpresas mais tarde e envolver membros das equipes de rede e infra–estrutura para ajudarem nesse processo.
Políticas e procedimentos de segurança
A diretiva de segurança determina o que os aplicativos podem fazer e o que os usuários do aplicativo têm permissão para fazer. O mais importante: ela define restrições para determinar o que os aplicativos e os usuários não podem fazer. Identifique e trabalhe com a estrutura definida pela diretiva de segurança da empresa ao projetar os aplicativos para garantir que você não está violando a diretiva, o que impedirá a implantação do aplicativo.
Componentes da infra–estrutura de rede
Certifique–se de que você entendeu a estrutura de rede do ambiente de destino e os requisitos básicos de segurança da rede em termos de regras de filtragem, restrições de porta, protocolos suportados e assim por diante.
Identifique como firewalls e suas diretivas podem afetar o projeto e a implantação do aplicativo. Pode haver firewalls para separar da rede interna os aplicativos ligados diretamente à Internet. Pode haver firewalls adicionais do banco de dados. Eles podem afetar as portas de comunicação possíveis e, portanto, as opções de autenticação do servidor Web para servidores de aplicativos e de banco de dados remotos. Por exemplo, a autenticação do Windows requer portas adicionais.
Na fase de projeto, considere quais protocolos, portas e serviços podem acessar os recursos internos a partir de servidores Web localizados na rede de perímetro. Identifique também os protocolos e as portas necessários ao projeto do aplicativo e analise as ameaças que podem surgir com a abertura de novas portas ou com o uso de novos protocolos.
Comunique e registre qualquer consideração sobre a segurança na camada da rede e do aplicativo e qual componente cuidará disso. Isso evita que faltem controles de segurança quando as equipes de desenvolvimento e de rede assumirem que a outra equipe está cuidado do assunto. Preste atenção às defesas de segurança que o aplicativo espera que a rede forneça. Considere as implicações de uma alteração na configuração da rede. Quanto você perderá de segurança se implementar uma alteração específica na rede?
Topologias de implantação
A topologia de implantação do aplicativo e se existe uma camada de aplicativo remota são considerações importantes a serem incorporadas ao seu projeto. Se existir uma camada de aplicativo remota, você terá que considerar como proteger a rede entre os servidores para eliminar a ameaça de espionagem da rede e para fornecer privacidade e integridade aos dados confidenciais.
Considere também identificar o fluxo e as contas que serão utilizadas para autenticação da rede quando o aplicativo conectar–se com servidores remotos. Uma abordagem comum é utilizar pelo menos uma conta de processo privilegiada e criar uma conta duplicada (espelho) no servidor remoto com a mesma senha. Como alternativa, convém utilizar uma conta de processo de domínio, que facilita a administração, mas é mais problemática de proteger devido à dificuldade de limitar o uso da conta pela rede. Um firewall intermediário ou domínios separados sem relações de confiança geralmente fazem com que a abordagem de conta local seja a única opção viável.
Intranet, extranet e Internet
Cada um desses cenários de uso do aplicativo apresenta desafios de projeto. As questões a considerar incluem: Como você conduzirá a identidade do chamador em várias camadas de aplicativo até os recursos back–end? Onde será feita a autenticação? Você pode confiar na autenticação feita no front–end e então utilizar uma conexão confiável para acessar recursos de back–end? No caso da extranet, você também deve considerar se confia nas contas dos parceiros.
Para obter mais informações sobre questões específicas para esses e outros cenários, consulte as seções “Intranet Security”, “Extranet Security” e “Internet Security” de “Building Secure ASP.NET Web Applications: Authentication, Authorization, and Secure Communication” em [url=”http://msdn.microsoft.com/library/en-us/dn…ecnetlpMSDN.asp”%5Dhttp://msdn.microsoft.com/library/en-us/dn…ecnetlpMSDN.asp%5B/url%5D (em inglês).
Validação da entrada
A validação da entrada é um desafio e o peso de uma solução cai sobre os ombros dos desenvolvedores do aplicativo. No entanto, a validação da entrada correta é uma das medidas de defesa mais fortes contra os ataques a aplicativos realizados atualmente. A validação da entrada correta é uma contramedida eficiente que pode ajudar a impedir ataques de scripts em sites, inclusão de código SQL e estouro do buffer, entre outros ataques de entrada.
A validação da entrada é difícil porque não há uma resposta única a o que constitui uma entrada válida entre os aplicativos e nem mesmo em cada aplicativo. Da mesma forma, não há uma única definição de entrada mal–intencionada. Além disso, o que o aplicativo faz com essa entrada influencia o risco de exploração. Por exemplo, você armazena dados para serem utilizados por outros aplicativos ou o seu aplicativo usa a entrada feita em outras fontes de dados por outros aplicativos?
As práticas a seguir melhoram a validação da entrada do aplicativo da Web:
• Considere que todas as entradas são mal–intencionadas.
• Centralize a sua abordagem.
• Não confie na validação do lado do cliente.
• Tenha cuidado com questões de canonização.
• Restrinja, rejeite e limpe a entrada.
Considere que todas as entradas são mal–intencionadas
A validação da entrada começa com a suposição fundamental de que toda entrada é mal–intencionada até que se prove o contrário. Independentemente de a entrada ter origem em um serviço, um compartilhamento de arquivo, um usuário ou de um banco de dados, valide a entrada se a fonte estiver fora do limite confiável. Por exemplo, se você chamar um Web Service externo que retornar seqüências de caracteres, como você sabe se não foram inseridos comandos mal–intencionados? Além disso, se houver vários aplicativos gravando dados em um banco de dados compartilhado, ao ler os dados, como saber se eles são seguros?
Centralize a sua abordagem
Faça da estratégia de validação da entrada um elemento básico do projeto do aplicativo. Considere uma abordagem centralizada para validação, por exemplo, utilizando um código comum de validação e filtragem em bibliotecas compartilhadas. Isso garante que as regras de validação serão aplicadas de forma consistente. Isso também reduz o trabalho de desenvolvimento e ajuda na manutenção futura.
Em muitos casos, campos individuais requerem validação específica, por exemplo, com expressões regulares desenvolvidas especialmente. No entanto, você pode freqüentemente melhorar rotinas comuns para validar campos utilizados regularmente, como endereços de email, cargos, nomes, endereços postais (incluindo CEP) e assim por diante.
Não confie na validação do lado do cliente
O código do lado do servidor deve executar sua própria validação. E se um invasor ignorar ou desativar as rotinas de script do lado do cliente, por exemplo, desativando o JavaScript? Use validação no lado do cliente para ajudar a reduzir o número de idas e vindas ao servidor, mas não confie nela para a segurança. Esse é um exemplo de defesa profunda.
Tenha cuidado com questões de canonização
Dados em forma canônica estão na sua forma padrão ou mais simples. Canonização é o processo de converter dados em sua forma canônica. Caminhos de arquivo e URLs são particularmente sujeitos a problemas de canonização e exploração bem conhecidas são o resultado direto de bugs de canonização. Por exemplo, considere a seqüência de caracteres a seguir que contém um arquivo e o caminho em sua forma canônica.
c:\temp\algumarquivo.dat
As seqüências de caracteres a seguir também poderiam representar o mesmo arquivo.
algumarquivo.dat
c:\temp\subdir\..\algumarquivo.dat
c:\ temp\ algumarquivo.dat
..\algumarquivo.dat
c%3A%5Ctemp%5Csubdir%5C%2E%2E%5Calgumarquivo.dat
No último exemplo, os caracteres foram especificados na forma hexadecimal:
• %3A representa o sinal dois–pontos.
• %5C representa uma barra invertida.
• %2E representa um ponto.
Geralmente, você deve tentar evitar projetar aplicativos que aceitam nomes de arquivo na entrada do usuário para evitar problemas de canonização. Em vez disso, considere projetos alternativos. Por exemplo, deixe o aplicativo determinar o nome do arquivo para o usuário.
Se você aceitar nomes de arquivo na entrada, certifique–se de que eles estejam estritamente formados antes de tomar decisões de segurança como autorizar ou negar acesso ao arquivo especificado.
Restrinja, rejeite e limpe a entrada
A melhor abordagem para validar a entrada é restringir desde o começo o que será permitido. É muito mais fácil validar dados de tipos, padrões e intervalos conhecidos que validá–los procurando caracteres inválidos conhecidos. Quando você projeta o aplicativo, sabe o que ele espera. O intervalo de dados válidos geralmente é um conjunto mais finito que o de entradas mal–intencionadas possíveis. No entanto, para uma defesa mais detalhada, convém rejeitar a entrada inválida conhecida e então limpá–la.
Para criar uma estratégia de validação da entrada eficiente, conheça as abordagens a seguir e suas exigências:
• Restringir a entrada.
• Validar dados por tipo, tamanho, formato e intervalo.
• Rejeitar dados inválidos.
• Limpar a entrada.
Restringir a entrada
Restringir a entrada refere–se a aceitar dados bons. Esta é a melhor abordagem. A idéia é definir um filtro de entradas aceitáveis utilizando tipo, tamanho, formato e intervalo. Defina o que é uma entrada aceitável para os campos do aplicativo e a aplique. Rejeite o restante como dados inválidos.
A restrição da entrada deve envolver a definição de conjuntos de caracteres no servidor para que você possa estabelecer a forma canônica da entrada de maneira localizada.
Validar os dados por tipo, tamanho, formato e intervalo
Use uma verificação de tipo rígida da entrada de dados sempre que possível, por exemplo, em classes utilizadas para manipular e processar os dados da entrada e em rotinas de acesso a dados. A exemplo disto, utilize procedimentos armazenados com parâmetros para acessar dados a fim de aproveitar a verificação de tipo dos campos de entrada.
Verifique também os campos de seqüências de caracteres e, muitas vezes, se seu formato é apropriado. Por exemplo, CEPs, números de RG, etc. têm formatos definidos que podem ser validados utilizando–se expressões regulares. A verificação completa não é a única boa prática de programação; ela dificulta que um invasor explore o código. O invasor pode passar pela verificação de tipo, mas a verificação de tamanho pode dificultar a execução de seu ataque favorito.
Rejeitar dados inválidos
Rejeite dados “inválidos”, mas não dependa totalmente dessa abordagem. Geralmente, ela é menos eficiente que utilizar a abordagem de “permissão” descrita anteriormente e é melhor usá–la de forma combinada. Para negar dados inválidos, assume–se que o aplicativo conhece todas as variações de uma entrada mal–intencionada. Lembre–se de que existem várias formas de representar caracteres. Esse é um outro motivo pelo qual a “permissão” é a abordagem preferida.
Embora seja útil para aplicativos que já estão em uso e quando você não pode arcar com alterações significativas, a abordagem de “negação” não é tão robusta como a de “permissão” pode os dados inválidos, como padrões que podem ser utilizados para identificar ataques comuns, não são constantes. Os dados válidos são constantes enquanto os dados inválidos podem variar periodicamente.
Limpar a entrada
Quando falamos em limpeza, significa transformar dados possivelmente mal–intencionados em dados seguros. Isso pode ser útil quando o intervalo de entrada permitido não pode garantir que a entrada é segura. Isso inclui qualquer coisa desde separar um valor nulo do final de uma seqüência de caracteres fornecida pelo usuário até remover valores para que sejam tratados como literais.
Outro exemplo comum de limpeza da entrada de aplicativos da Web é utilizar codificação de URL ou HTML para combinar dados e tratá–los como texto literal em vez de como script executável. Os métodos de HtmlEncode removem caracteres HTML e UrlEncode codificam um URL para que ele seja uma solicitação URI válida.
Na prática
Seguem exemplos aplicados a campos de entrada comuns utilizando as abordagens citadas:
• Campo Sobrenome. Este é um bom exemplo de onde a restrição da entrada é apropriada. Nesse caso, convém restringir os dados da seqüência de caracteres no intervalo ASCII A–Z e a–z e também em hífens e apóstrofes (apóstrofes não significam nada para o SQL) para tratar nomes como O’Dell. Também é ideal limitar a extensão ao maior valor esperado.
• Campo Quantidade. Este é outro caso em que a restrição da entrada funciona bem. Neste exemplo, convém utilizar uma restrição simples de tipo e intervalo. Por exemplo, os dados da entrada podem precisar ser um número inteiro positivo entre 0 e 1000.
• Campo Texto livre. Os exemplos incluem campos de comentário em quadros de discussão. Nesse caso, convém permitir o uso de letras e espaços além de caracteres comuns, como apóstrofes, vírgulas e hífens. O conjunto do que é permitido não inclui sinais de maior que e menor que, chaves e colchetes.
Alguns aplicativos podem permitir que os usuários marquem o texto utilizando um conjunto finito de caracteres de script, como negrito “” e itálico ““, ou até mesmo incluam um link para o URL favorito. No caso de um URL, a validação deve codificar o valor para que ele seja tratado como URL.
Um aplicativo da Web existente que não valida a entrada do usuário. Em um cenário ideal, o aplicativo verifica se a entrada de cada campo ou ponto de entrada é aceitável. No entanto, se você já possui um aplicativo da Web que não valida a entrada do usuário, você precisa de uma abordagem “quebra galho” para reduzir o risco até que seja possível aprimorar a estratégia de validação da entrada do aplicativo. Embora nenhuma das abordagens a seguir garantam um tratamento seguro da entrada, pois dependem de fatores como de onde vem a entrada e como ela será utilizada no aplicativo, elas são empregadas atualmente como correções rápidas para melhorar a segurança em curto prazo:
• Codificar como HTML e URL a entrada do usuário ao gravar de volta no cliente. Nesse caso, considera–se que nenhuma entrada é tratada como HTML e todas as saída são gravadas de volta de forma protegida. Essa é uma ação de limpeza.
• Rejeitar caracteres de script mal-intencionados. Esse é um caso de rejeição de entrada inválida conhecida. Nesse caso, um conjunto configurável de caracteres mal–intencionados é utilizado para rejeitar a entrada. Como descrito anteriormente, o problema dessa abordagem é um dado considerado inválido de acordo com o contexto.
Autenticação
Autenticação é o processo pelo qual se determina a identidade do chamador. Existem três aspectos a considerar:
• Identificar onde a autenticação é necessária no aplicativo. Geralmente, ela é requerida sempre que um limite confiável é ultrapassado. Os limites confiáveis normalmente incluem conjuntos, processos e hosts.
• Validar quem é o chamador. Os usuários geralmente se autenticam com nomes de usuário e senhas.
• Identificar o usuário nas solicitações subseqüentes. Isso requer alguma forma de identificador de autenticação.
Muitos aplicativos da Web usam um mecanismo de senha para autenticar usuários, sendo que o usuário fornece um nome de usuário e uma senha em formato HTML. As questões a considerar nesse caso incluem:
• Os nomes de usuário e senhas são enviados em texto sem formatação por um canal inseguro? Se sim, um invasor pode utilizar um software de monitoramento de rede para espionar e capturar as credenciais. A contramedida aqui é proteger o canal de comunicação utilizando SSL (Secure Socket Layer).
• Como as credenciais são armazenadas? Se você estiver armazenando nomes de usuário e senhas em texto sem formatação, em arquivos ou em um banco de dados, está procurando problemas. E se o diretório do aplicativo não estiver configurado corretamente e um invasor procurar um arquivo e baixar seu conteúdo ou incluir uma conta de logon com privilégios? E se um administrador descontente levar seu banco de dados de nomes de usuário e senhas?
• Como as credenciais são verificadas? Não é necessário armazenar senhas de usuário se a única finalidade for verificar se o usuário conhece a senha. Em vez disso, você pode armazenar um verificador na forma de um valor de hash e recalcular o hash utilizando o valor fornecido pelo usuário durante o processo de logon. Para eliminar a ameaça de um ataque de dicionário contra o armazenamento de credenciais, utilize senhas de alta segurança e combine um valor falso gerado aleatoriamente com o hash da senha.
• Como o usuário autenticado é identificado após o logon inicial? É necessária alguma forma de permissão de autenticação como, por exemplo, um cookie de autenticação. Como o cookie é protegido? Se ele for enviado por um canal desprotegido, um invasor pode capturá–lo e usá–lo para acessar o aplicativo. Um cookie de autenticação roubado é um logon roubado.
As práticas a seguir melhoram a autenticação do aplicativo da Web:
• Separar áreas públicas e restritas.
• Utilizar diretivas de bloqueio de conta para as contas de usuário final.
• Utilizar senhas com data de validade.
• Poder desativar contas.
• Não armazenar senhas nos armazenamentos de usuários.
• Exigir senhas de alta segurança.
• Não transmitir senhas em texto sem formatação.
• Proteger os cookies de autenticação.
Separar áreas públicas e restritas
A área pública do seu site pode ser acessada por qualquer usuário de forma anônima. As áreas restritas só podem ser acessadas por pessoas específicas e os usuários devem ser autenticados no site. Considere um site comum de uma loja. Você pode navegar pelo catálogo de produtos de forma anônima. Quando você inclui itens no carrinho de compra, o aplicativo identifica você utilizando um identificador de sessão. Finalmente, quando você faz o pedido, realiza uma transação segura. Nesse ponto, você precisa fazer logon para autenticar sua transação pela SSL.
Dividindo o site em áreas de acesso pública e restrita, você pode aplicar regras de autenticação e autorização a todo o site e limitar o uso da SSL. Para evitar a sobrecarga desnecessária sobre o desempenho provocado pela SSL, projete o site de modo a limitar o uso da SSL nas áreas que requerem acesso autenticado.
Utilizar diretivas de bloqueio de conta para as contas de usuário final
Desative contas de usuário final ou a gravação de eventos em log depois de um número determinado de tentativas de logon sem sucesso. Se você estiver utilizando a autenticação do Windows, como NTLM ou o protocolo Kerberos, essas diretivas podem ser configuradas e aplicadas automaticamente pelo sistema operacional. Com autenticação de formulários, essas diretivas são responsabilidade do aplicativo e devem ser incorporadas ao projeto do mesmo.
Tenha cuidado para que as diretivas de bloqueio de contas não sejam utilizadas em ataques de negação de serviço. Por exemplo, contas de serviço padrão conhecidas, como IUSR_MACHINENAME, devem ser substituída por nomes de contas personalizados para evitar que um invasor que consiga obter o nome do servidor Web do IIS (Internet Information Services) bloqueie essa conta vital.
Utilizar senhas com data de validade
As senhas não devem ser estáticas e sim alteradas como parte da rotina de manutenção de senha por meio de períodos de validade da senha. Considere fornecer esse tipo de recurso ao projetar o aplicativo.
Poder desativar contas
Se o sistema estiver comprometido, poder invalidar deliberadamente credenciais ou desativar contas pode evitar outros ataques.
Não registrar senhas nos armazenamentos de usuários
Se você deve verificar as senhas, não é necessário realmente armazená–las. Em vez disso, armazene um valor de hash unidirecional e então recalcule o hash utilizando as senhas fornecidas pelos usuários. Para eliminar a ameaça de um ataque de dicionário contra o armazenamento do usuário, utilize senhas de alta segurança e incorpore um valor falso gerado com a senha.
Exigir senhas de alta segurança
Não facilite a quebra de senhas para os invasores. Existem muitas instruções, mas uma prática geral é exigir no mínimo oito caracteres e uma mistura de letras maiúsculas e minúsculas, números e caracteres especiais. Tanto se você estiver utilizando uma plataforma para aplicar essas regras ou quanto se estiver desenvolvendo sua própria validação, essa etapa é necessária para combater ataques de força bruta, nos quais o invasor tenta quebrar uma senha sistematicamente por tentativa e erro. Utilize expressões regulares para ajudar na validação de senhas de alta segurança.
Não transmitir senhas em texto sem formatação
Senhas em texto sem formatação enviadas por uma rede ficam vulneráveis à espionagem. Para acabar com essa ameaça, você precisa proteger o canal de comunicação como, por exemplo, utilizar SSL para criptografar o tráfego.
Proteger os cookies de autenticação
Um cookie de autenticação roubado é um logon roubado. Proteja as permissões de autenticação utilizando criptografia e canais de comunicação seguros. Além disso, limite o tempo de validade de uma permissão de autenticação para combater a ameaça de spoofing que pode resultar de ataques de repetição, nos quais o invasor captura o cookie e o usa para obter acesso ilegal ao site. Reduzir o tempo limite do cookie não evita ataques de repetição, mas limita o tempo pelo qual o invasor terá acesso ao site utilizando o cookie roubado.
Autorização
A autorização determina o que a identidade autenticada pode realizar e quais recursos ela acessa. Uma autorização incorreta ou ineficaz leva à divulgação de informações e à violação dos dados. Defesa profunda é o princípio básico de segurança utilizado na estratégia de autorização do aplicativo.
As práticas a seguir melhoram a autorização do aplicativo da Web:
• Utilizar vários gatekeepers.
• Restringir o acesso do usuário a recursos no nível do sistema.
• Considerar a granulação da autorização.
Utilizar vários gatekeepers
No lado do servidor, você pode utilizar as diretivas do IPSec (IP Security Protocol) para definir restrições do host a fim de restringir a comunicação entre servidores. Por exemplo: uma diretiva IPSec poderia restringir a conexão de qualquer host separado de um servidor Web com um servidor de banco de dados. O IIS fornece permissões da Web e restrições IP/DNS (Internet Protocol/Domain Name System). As permissões da Web do IIS são válidas para todos os recursos solicitados pelo HTTP independentemente do usuário. Elas não oferecem proteção se um invasor tiver como realizar logon no servidor. Por isso, as permissões de NTFS consentem que você especifique listas de controle de acesso por usuário. Finalmente, o ASP.NET fornece autorização de URL e de arquivo junto a demanda de permissão principal. Combinando esses gatekeepers, você pode desenvolver uma estratégia de autorização eficiente.
Restringir o acesso do usuário a recursos no nível do sistema
Os recursos no nível do sistema incluem arquivos, pastas, chaves do registro, objetos do Active Directory, objetos do banco de dados, logs de evento, etc. Utilize as listas de controle de acesso do Windows para restringir quais usuários podem acessar quais recursos e os tipos de operação que eles podem executar. Preste atenção especialmente nas contas de usuário anônimas da Internet; utilize as listas de controle de acesso para restringi–las a recursos que negam acesso explicitamente a usuários anônimos.
Considerar a granulação da autorização
Existem três modelos comuns de autorização, cada um com graus diferentes de granulação e escalabilidade.
A abordagem mais granular depende de representação. O acesso aos recursos ocorre utilizando o contexto de segurança do chamador. As listas de controle de acesso do Windows dos recursos protegidos (geralmente arquivos ou tabelas, ou ambos) determinam se o chamador pode acessar o recurso. Se o aplicativo fornecer acesso basicamente a recursos específicos do usuário, essa abordagem pode ser válida. Sua vantagem é que a auditoria no nível do sistema operacional pode ser feita entre as camadas do aplicativo, pois o contexto de segurança do chamador original flui no nível do sistema operacional e é utilizado para acessar recursos. No entanto, seu problema é a escalabilidade do aplicativo, pois não é possível estabelecer um pool de conexão eficiente para acessar o banco de dados. Como resultado, essa abordagem é encontrada com mais freqüência em aplicativos para intranet de escala limitada.
A abordagem menos granular, porém mais escalonável, utiliza a identificação de processo do aplicativo para acessar recursos. Ela oferece suporte ao pool de conexão ao banco de dados, mas isso significa que as permissões concedidas à identificação do aplicativo no banco de dados são comuns, independentemente da identificação do chamador original. A autorização principal é feita na camada intermediária lógica do aplicativo utilizando funções, agrupando usuários que compartilham os mesmos privilégios com relação ao aplicativo. O acesso a classes e métodos é restringido de acordo com a participação do chamador na função. Para oferecer suporte à recuperação de dados por usuário, uma abordagem comum é inclui uma coluna de identificação nas tabelas do banco de dados e utilizar parâmetros de consulta para restringir os dados recuperados. Por exemplo: você pode passar a identificação do chamador original para o banco de dados no nível do aplicativo (não do sistema operacional) por meio de parâmetros de procedimentos armazenados e gravar consultas semelhantes a estas:
SELECT field1, field2, field3 FROM Table1 WHERE {some search criteria} AND
UserName = @originalCallerUserName
Esse modelo é conhecido como subsistema confiável ou, às vezes, como modelo de servidor confiável.
A terceira opção é utilizar um conjunto limitado de identidades para acessar recursos com base na participação do chamador na função. Na verdade, trata–se de um híbrido dos dois modelos descritos anteriormente. Os chamadores são mapeados para funções na camada intermediária lógica do aplicativo e o acesso a classes e métodos é restrito de acordo com a participação na função. O acesso a recursos de downstream é feito utilizando um conjunto restrito de identidade determinado pela participação na função do chamador atual. A vantagem dessa abordagem é que as permissões podem ser atribuídas a logons separados no banco de dados e a regulagem da conexão ainda ser efetiva com diversos pools de conexões. A desvantagem é que a criação dos símbolos de acesso com vários segmentos utilizados para estabelecer contextos diferentes de segurança para acessar recursos de downstream utilizando a autenticação do Windows é uma operação com privilégios que requer contas de processo com privilégios. Isso vai contra o princípio de menos privilégios.
Gerenciamento de configuração
Considere atentamente a funcionalidade de gerenciamento de configuração do aplicativo da Web. A maioria dos aplicativos requer interfaces que permitem que desenvolvedores de conteúdo, operadores e administradores configurem o aplicativo e gerenciem itens como conteúdo de páginas da Web, contas de usuário, informações do perfil do usuário e seqüências de caracteres para conexão do banco de dados. Se houver suporte para administração remota, como as interfaces de administração são protegidas? As conseqüências de uma falha de segurança em uma interface administrativa podem ser graves, pois o invasor freqüentemente acaba utilizando privilégios de administrador e tem acesso direto a todo o site.
As práticas a seguir aumentam a segurança do gerenciamento da configuração do aplicativo da Web:
• Proteger as interfaces administrativas.
• Proteger o armazenamento da configuração.
• Manter privilégios administrativos distintos.
• Utilizar contas com processos e serviços com a menor quantidade de privilégios.
Proteger as interfaces administrativas
É importante que a funcionalidade de gerenciamento da configuração seja acessível somente por operadores e administradores autorizados. O principal é aplicar uma autenticação rígida nas interfaces administrativas, por exemplo, utilizando certificados.
Se possível, limite ou evite o uso da administração remota e exija que os administradores façam logon localmente. Se você precisar oferecer suporte a administração remota, use canais criptografados, por exemplo, com tecnologia de SSL VPN, devido à natureza confidencial dos dados transmitidos pelas interfaces administrativas. Considere também limitar a administração remota a computadores da rede interna utilizando diretivas IPSec para diminuir ainda mais o risco.
Proteger o armazenamento da configuração
Arquivos de configuração em texto, o registro e os bancos de dados são as opções comuns para armazenamento dos dados de configuração do aplicativo. Se possível, evitar utilizar arquivos de configuração no espaço da Web do aplicativo para evitar possíveis vulnerabilidades no servidor de configuração, resultando no download dos arquivos de configuração. Independentemente da abordagem utilizada, proteja o acesso ao armazenamento da configuração, por exemplo, utilizando as listas de controle de acesso do Windows ou permissões do banco de dados. Além disso, evite armazenar informações confidenciais, como seqüências de caracteres de conexão do banco de dados ou credenciais de contas, em texto sem formatação. Proteja esses itens utilizando criptografia e restrinja o acesso à chave do registro, ao arquivo ou à tabela que contém os dados criptografados.
Manter privilégios administrativos distintos
Se a funcionalidade suportada pelos recursos do gerenciamento da configuração do aplicativo varia de acordo com a função do administrador, considere autorizar cada função separadamente utilizando a autorização com base na função. Por exemplo: a pessoa responsável por atualizar o conteúdo estático do site não precisa ter permissão para alterar o limite de crédito de um cliente.
Utilizar contas com processos e serviços com a menor quantidade de privilégios
Um aspecto importante da configuração do aplicativo são as contas de processo utilizadas para executar processos no servidor Web e as contas de serviço utilizadas para acessar recursos de downstream e sistemas. Certifique–se de que essas contas estejam configuradas com a menor quantidade de privilégios. Se um invasor conseguir assumir o controle de um processo, a identificação do processo deve ter acesso extremamente restrito ao sistema de arquivos e a outros recursos do sistema para limitar os danos que podem ser causados
Dados confidenciais
Os aplicativos que lidam com informações particulares dos usuários, como números de cartão de crédito, endereços, registros médicos e outros, devem seguir etapas especiais para garantir que os dados permanecerão particulares e inalterados. Além disso, os segredos utilizados na implementação do aplicativo, como senhas e seqüências de conexão ao banco de dados, devem ser protegidos. A segurança de dados confidenciais é um problema enquanto os dados são armazenados em um local de armazenamento persistente e enquanto são transmitidos pela rede.
Segredos
Os segredos incluem senhas, seqüências de caracteres de conexão ao banco de dados e números de cartão de crédito. As práticas a seguir aumentam a segurança do tratamento dos segredos feito pelo aplicativo da Web:
• Não armazenar segredos se for possível evitar.
• Não armazenar segredos no código.
• Não armazenar conexões ao banco de dados, senhas ou chaves em texto sem formatação.
• Evitar armazenar segredos na LSA (autoridade de segurança local).
• Utilizar a DAPI (API de Proteção a Dados) para criptografar os segredos.
Não armazenar segredos se for possível evitar
Armazenar segredos em software de maneira totalmente segura é impossível. Um administrador, com acesso físico ao servidor, pode acessar os dados. Não é necessário armazenar um segredo quando tudo o que você precisa fazer é verificar se o usuário o conhece. Nesse caso, você pode armazenar um valor de hash que representa o segredo e calcula o hash utilizando o valor fornecido pelo usuário para verificar se o usuário conhece o segredo.
Não armazenar segredos no código
Não inclua os segredos no código. Mesmo que o código–fonte não seja exposto no servidor Web, é possível extrair constantes de seqüências de caracteres de arquivos executáveis compilados. Uma vulnerabilidade na configuração pode permitir que um invasor recupere o executável.
Não armazenar conexões ao banco de dados, senhas ou chaves em texto sem formatação
Evite armazenar segredos como seqüências de caracteres de conexões ao banco de dados, senhas ou chaves em texto sem formatação. Utilize criptografia e armazene seqüências de caracteres criptografadas.
Evitar armazenar segredos na LSA
Evitar a LSA porque o aplicativo requer privilégios administrativos para acessá–la. Isso viola o princípio de segurança básico de utilizar a menor quantidade de privilégios. Além disso, a LSA pode armazenar segredos somente em um número restrito de slots. O melhor é utilizar a DPAPI, disponível no Microsoft Windows® 2000 e nos sistemas operacionais posteriores.
Utilizar DPAPI para criptografar os segredos
Para armazenar segredos como seqüências de caracteres de conexão a banco de dados ou credenciais de serviço das contas, use DPAPI. A principal vantagem de utilizar a DPAPI é que o sistema da plataforma gerencia a chave de criptografia/descriptografia e isso não é problema para o aplicativo. A chave é vinculada a uma conta de usuário do Windows ou a um computador específico, dependendo dos sinalizadores passados para as funções da DPAPI.
A DPAPI é mais adequada para criptografar informações, pois pode ser recriada manualmente em caso de perda das chaves mestre, por exemplo, devido a um dano no servidor que exija a reinstalação do sistema operacional. Dados que não podem ser recuperados porque você conhece o valor sem formatação, por exemplo, detalhes do cartão de crédito do cliente, requerem uma abordagem alternativa que usa a criptografia com base em chave simétrica tradicional, como a utilizada no triplo DES.
Dados confidenciais por usuário
Dados confidenciais, como credenciais de logon, e dados no nível do aplicativo, como números de cartão de crédito, números de contas bancárias, etc., precisam ser protegidos. A privacidade por meio da criptografia e a integridade através de códigos de autenticação de mensagens (MAC) são os elementos principais.
As práticas a seguir aumentam a segurança de dados confidenciais por usuário em aplicativos da Web:
• Recuperar dados confidenciais sob demanda.
• Criptografar os dados ou proteger o canal de comunicação.
• Não armazenar dados confidenciais em cookies persistentes.
• Não transmitir dados confidenciais utilizando o protocolo HTTP–GET.
Recuperar dados confidenciais sob demanda
A melhor abordagem é recuperar dados confidenciais sob demanda quando eles forem necessários em vez de mantê–los ou armazená–los em cache na memória. Por exemplo: recupere o segredo criptografado quando ele for necessário, descriptografe–o e limpe a memória (variável) uutilize para manter o segredo em texto sem formatação. Se a questão for o desempenho, considere estas opções:
• Armazenar em cache o segredo criptografado.
• Armazenar em cache o segredo em texto sem formatação.
Armazenar em cache o segredo criptografado
Recupere o segredo quando o aplicativo for carregado e o armazene em cache na memória, descriptografando–o quando o aplicativo usá–lo. Apague a cópia em texto sem formatação quando ela não for mais necessária. Essa abordagem evita o acesso ao armazenamento de dados a cada solicitação.
Armazenar em cache o segredo em texto sem formatação
Evite a sobrecarga de descriptografar o segredo várias vezes e armazenar a cópia em texto sem formatação do segredo na memória. Essa é a abordagem menos segura, mas oferece o melhor desempenho. Teste as outras abordagens antes de achar que o ganho em desempenho compensa o risco de segurança maior.
Criptografar os dados ou proteger o canal de comunicação
Se você estiver enviando ao cliente dados confidenciais pela rede, criptografe–os ou proteja o canal. Uma prática comum é utilizar SSL entre o cliente e o servidor Web. Entre servidores, a abordagem cada vez mais comum é utilizar IPSec. Para proteger dados confidenciais que trafegam entre vários intermediários, por exemplo, mensagens SOAP (Simple Object Access Protocol) do Web Service, usam criptografia no nível da mensagem.
Não armazenar dados confidenciais em cookies persistentes
Evite armazenar dados confidenciais em cookies persistentes. Se você armazenar dados em texto sem formatação, o usuário final poderá ver e modificar os dados. Se você criptografar os dados, o gerenciamento de chaves pode ser um problema. Por exemplo, a chave utilizada para criptografar os dados no cookie expirou e foi reciclada, a nova chave não consegue descriptografar o cookie persistente transmitido pelo navegador a partir do cliente.
Não transmitir dados confidenciais utilizando o protocolo HTTP–GET
Você pode evitar armazenar dados confidenciais utilizando o protocolo HTTP–GET porque ele usa seqüências de caracteres de consulta para transmitir dados. Não é possível proteger dados confidenciais utilizando seqüências de caracteres de consulta e estas são freqüentemente registradas pelo servidor
Gerenciamento de sessão
Os aplicativos da Web baseiam–se no protocolo HTTP independente, portanto, o gerenciamento da sessão é responsabilidade do aplicativo. A segurança da sessão é fundamental para a segurança geral do aplicativo.
As práticas a seguir aumentam a segurança do gerenciamento da sessão do aplicativo da Web:
• Utilizar SSL para proteger os cookies de autenticação da sessão.
• Criptografar o conteúdo dos cookies de autenticação.
• Limitar a duração da sessão.
• Proteger o estado da sessão contra acesso não autorizado.
Utilizar SSL para proteger os cookies de autenticação da sessão
Não transmita cookies de autenticação por conexões HTTP. Defina o cookie seguro corretamente nos cookies de autenticação, que instruem os navegadores a retornar os cookies ao servidor somente por conexões HTTPS.
Criptografar o conteúdo dos cookies de autenticação
Criptografe o conteúdo do cookie mesmo que você esteja utilizando SSL. Isso evita que um invasor visualize ou modifique o cookie se ele conseguir roubá–lo por meio de um ataque de scripts através de sites. Nesse caso, o invasor ainda poderia utilizar o cookie para acessar o aplicativo, mas somente enquanto ele fosse válido.
Limitar a duração da sessão
Reduza o tempo de duração das sessões para reduzir o risco de seqüestro de sessão e ataques de repetição. Quanto menor a sessão, menos tempo o invasor terá para capturar um cookie da sessão usá–lo para acessar o aplicativo.
Proteger o estado da sessão contra acesso não autorizado
Considere como o estado da sessão será armazenado. Para um melhor desempenho, você pode armazená–lo no espaço de endereço do processo do aplicativo da Web. No entanto, essa abordagem tem escalabilidade limitada e implicações em cenários de Web farm, nos quais não há garantia de que as solicitações do mesmo usuário serão tratadas pelo mesmo servidor. Nesse caso, é necessário um estado fora do processo em um servidor de estado dedicado ou um armazenamento de estado persistente em um banco de dados compartilhado. O ASP.NET suporte as três opções.
Você deve proteger o link de rede entre o aplicativo da Web e o armazenamento de estado utilizando IPSec ou SSL para reduzir o risco de espionagem. Considere também como o aplicativo da Web será autenticado pelo armazenamento de estado. Utilize a autenticação do Windows sempre que possível para evitar transmitir credenciais de autenticação em texto sem formatação pela rede e para aproveitar as diretivas de contas seguras do Windows.
Criptografia
A criptografia em sua forma básica oferece o seguinte:
• Privacidade (Confidencialidade). Esse serviço mantém um segredo como confidencial.
• Não-repúdio (Autenticidade). Esse serviço garante que um usuário não pode negar o envio de uma mensagem em particular.
• À prova de violação (Integridade). Esse serviço evita que os dados sejam alterados.
• Autenticação. Esse serviço confirma a identidade do remetente de uma mensagem.
Os aplicativos da Web freqüentemente usam criptografia para protege dados em armazenamentos persistentes ou enquanto são transmitidos pelas redes. As práticas a seguir aumentam a segurança do aplicativo da Web quando você utilizar criptografia:
• Não desenvolver sua própria criptografia.
• Manter dados descriptografados próximos do algoritmo.
• Utilizar o algoritmo e o tamanho de chave corretos.
• Proteger as chaves de criptografia.
Não desenvolver sua própria criptografia
Algoritmos e rotinas de criptografia são notoriamente difíceis de desenvolver com sucesso. Como resultado, você deve utilizar os serviços de criptografia testados fornecidos pela plataforma. Isso inclui o .NET Framework e o sistema operacional subjacente. Não desenvolva implementações personalizadas porque, geralmente, resultam em uma proteção fraca.
Manter dados descriptografados próximos do algoritmo
Ao transmitir texto sem formatação a um algoritmo, não obtenha os dados até que você esteja pronto para usá–los e armazená–los no menor número de variáveis possível.
Utilizar o algoritmo e o tamanho de chave corretos
É importante garantir que você escolheu o algoritmo certo para o trabalho certo e que você está utilizando um tamanho de chave que fornece um grau suficiente de segurança. Chaves maiores geralmente aumentar a segurança. A lista a seguir resume os principais algoritmos com o tamanho de chave que cada um usa:
• Chave DES (Data Encryption Standard) de 64 bits (8 bytes)
• Chave triplo DES de 128 bits ou chave de 192 bits (16 ou 24 bytes)
• Chaves Rijndael de 128 – 256 bits (16 – 32 bytes)
• Chaves RSA de 384 – 16.384 bits (48 – 2.048 bytes)
Para criptografar dados maiores, utilize o algoritmo de criptografia simétrica Triplo DES. Para criptografia mais lenta e mais rígida de grandes quantidades de dados, use Rijndael. Para criptografar os dados que serão armazenados por curtos períodos, você pode considerar o uso de um algoritmo mais rápido, mas mais fraco, como o DES. Para assinaturas digitais, utilize RSA (Rivest, Shamir e Adleman) ou DAS (Digital Signature Algorithm). Para hash, utilize o SHA (Secure Hash Algorithm)1.0. Para hashes com chaves, utilize o HMAC (Hash–based Message Authentication Code) SHA1.0.
Proteger as chaves de criptografia
A chave de criptografia é um número secreto utilizado como entrada para processos de criptografia e descriptografia. Para que os dados criptografados continuem seguros, a chave deve ser protegida. Se um invasor comprometer a chave de descriptografia, os dados criptografados não estarão mais seguros.
As práticas a seguir ajudam a proteger as chaves de criptografia:
• Utilizar a DPAPI para evitar o gerenciamento de chaves.
• Mudar as chaves periodicamente.
Utilizar a DPAPI para evitar o gerenciamento de chaves
Como já foi citado, uma das maiores vantagens do uso da DPAPI é que a questão do gerenciamento de chaves fica a cargo do sistema operacional. A chave utilizada pela DPAPI é derivada da senha associada à conta de processo que aciona as funções da DPAPI. Use a DPAPI para deixar o trabalho de gerenciamento de chaves para o sistema operacional.
Mudar as chaves periodicamente
Geralmente, a probabilidade de um segredo estático ser descoberto com o tempo é maior. As questões que você não pode esquecer incluem: Você o anotou em algum lugar? Bob, o administrador que detém os segredos, mudou de cargo ou saiu da empresa? Não use demais as chaves.
Manipulação de parâmetros
Com ataques de manipulação de parâmetros, o invasor modifica os dados transmitidos entre o cliente e o aplicativo da Web. Podem ser dados enviados por meio de seqüências de caracteres de consulta, campos de formulário, cookies ou em cabeçalhos HTTP. As práticas a seguir ajudam a proteger a manipulação de parâmetros do aplicativo da Web:
• Criptografar o estado de cookies confidenciais.
• Certificar–se de que os usuários não ignoram as verificações.
• Validar todos os valores enviados a partir do cliente.
• Não confiar nas informações do cabeçalho HTTP.
Criptografar o estado de cookies confidenciais
Os cookies podem conter dados confidenciais, como identificadores de sessão, ou dados utilizados no processo de autorização do lado do servidor. Para proteger esse tipo de dados contra manipulação não–autorizada, criptografe o conteúdo do cookie.
Certificar–se de que os usuários não ignoram as verificações
Certifique–se de que os usuários não ignoram as verificações manipulando parâmetros. Os parâmetros de URL podem ser manipulados pelos usuários finais através da caixa de texto de endereço do navegador. Por exemplo: o URL [url=”http://www.//IDsessão=10″%5Dhttp://www.//IDsessão=10%5B/url%5D possui um valor de 10 que pode ser alterado para algum número aleatório para receber uma saída diferente. Certifique–se de verificar isso no código do lado do servidor, não no JavaScript no lado do cliente, que pode ser desativado no navegador.
Validar todos os valores enviados a partir do cliente
Restrinja os campos que o usuário pode inserir e modificar e valide todos os valores provenientes do cliente. Se você predefiniu valores em campos de formulário, os usuários podem alterá–los e retorná–los para receber resultados diferentes. Permita somente valores bem conhecidos sempre que possível. Por exemplo, se o campo de entrada for um estado, somente entradas que correspondam ao código postal do estado devem ser permitidas.
Não confiar nas informações do cabeçalho HTTP
Os cabeçalhos HTTP são enviados no início das solicitações e das respostas HTTP. O aplicativo da Web deve certificar–se de que ele não baseia nenhuma decisão de segurança nas informações contidas nos cabeçalhos HTTP porque é fácil para um invasor manipular o cabeçalho. Por exemplo, o campo referencial do cabeçalho contém o URL da página da Web de onde ele provém. Não tome decisões de segurança com base no valor do campo referencial, por exemplo, verificar se a solicitação teve origem em uma página gerada pelo aplicativo da Web, pois o campo pode ser facilmente falsificado.
Gerenciamento de exceções
O tratamento seguro de exceções pode ajudar a evitar certos ataques de negação de serviço no nível do aplicativo e também pode ser utilizado para impedir que informações importantes no nível do sistema úteis aos invasores sejam retornadas ao cliente. Por exemplo, sem o tratamento correto de exceções, informações como detalhes do esquema do banco de dados, versões do sistema operacional, rastreamentos de pilha, nomes e caminho de arquivos, seqüências de caracteres de consulta do SQL e outras informações de valor para o invasor podem ser retornadas ao cliente.
Uma boa abordagem é projetar um gerenciamento de exceções centralizado e uma solução de registro em log e considerar a inclusão de ganchos no sistema de gerenciamento de exceções para oferecer suporte à instrumentação e ao monitoramento centralizado para ajudar os administradores de sistema.
As práticas a seguir ajudam a proteger o gerenciamento de exceções do aplicativo da Web:
• Não deixar vazar informações para o cliente.
• Registrar em log mensagens de erro com detalhes.
• Identificar as exceções.
Não deixar vazar informações para o cliente
No caso de falha, não exponha informações que poderiam resultar na divulgação de informações. Por exemplo, não exponha detalhes do rastreamento de pilha que incluam nomes de função e números de linha no caso de compilações para depuração (que não devem ser utilizadas em servidores de produção). Em vez disso, retorne mensagens de erro genéricas ao cliente.
Registrar em log mensagens de erro com detalhes
Envie mensagens de erro detalhadas ao log de erros. Envie o mínimo de informações ao usuário do serviço ou do aplicativo, como uma mensagem de erro genérica e uma identificação personalizada do log de erro que possa ser então mapeada até a mensagem detalhada nos logs de eventos. Certifique–se de não registrar no log senhas nem outros dados confidenciais.
Identificar as exceções
Utilize um tratamento de exceções estruturado e identifique condições de exceção. Isso evita que o aplicativo fique com um estado inconsistente que pode resulta na divulgação de informações. Isso também pode ajudar a proteger o aplicativo contra ataques de negação de serviço. Decida como propagar as exceções internamente no aplicativo e dê atenção especial a o que ocorre no limite do aplicativo.
Auditoria e log
Você deve executar atividades de auditoria e log nas camadas do aplicativo. Utilizando logs, é possível detectar atividades suspeitas. Elas freqüentemente indicam com antecedência um ataque devastador e os logs ajudam a resolver o risco de recusa quando os usuários recusam suas ações. Os arquivos de log podem ser exigidos em processos judiciais para provarem a transgressão dos acusados. Geralmente, o processo de auditoria é considerado mais autorizado se as auditorias forem geradas no momento exato em que um recurso é acessado e pelas mesmas rotinas que acessam o recurso.
As práticas a seguir aumentam a segurança do aplicativo da Web:
• Auditar e registrar em log o acesso entre as camadas do aplicativo.
• Considerar o fluxo de identificação.
• Registrar em log eventos importantes.
• Proteger arquivos de log.
• Fazer backup dos arquivos de log e os analisar regularmente.
Auditar e registrar em log o acesso entre as camadas do aplicativo
Audite e registre em log o acesso entre as camadas do aplicativo no caso de não–repúdio. Use uma combinação de log no nível do aplicativo e recursos de auditoria da plataforma, como a auditoria do Windows, do IIS e do SQL Server.
Considerar o fluxo de identificação
Considere como o aplicativo transmitirá a identificação do chamador entre as várias camadas do aplicativo. Você tem duas opções básicas. Você pode transmitir a identificação do chamador no nível do sistema operacional utilizando a delegação do protocolo Kerberos. Isso permite o uso da auditoria no nível do sistema operacional. A desvantagem dessa abordagem é que ela afeta a escalabilidade, pois significa que não pode haver nenhum pool de conexão do banco de dados ativo na camada intermediária. Como alternativa, você pode transmitir a identificação do chamador no nível do aplicativo e utilizar identificações confiáveis para acessar recursos de back–end. Com essa abordagem, você tem que confiar na camada intermediária e existe um risco de recuso. Você deve gerar faixas de auditoria na camada intermediária que possam ser correlacionadas às faixas de auditoria de back–end. Para isso, você deve certificar–se de que os relógios dos servidores estão sincronizados, embora o Microsoft Windows 2000 e o Active Directory façam isso por você.
Registrar em log eventos importantes
Os tipos de eventos que devem ser registrados incluem tentativas de logon bem–sucedidas ou não, modificação de dados, recuperação de dados, comunicações de rede e funções administrativas, como ativar ou desativar o registro em log. Os logs devem inclui a hora do evento, a localização do evento incluindo o nome da máquina, a identificação do usuário atual, a identificação do processo que iniciou o evento e uma descrição detalhada do evento.
Proteger arquivos de log
Proteja os arquivos de log utilizando as listas de controle de acesso do Windows e restrinja o acesso a eles. Isso dificulta para os invasores a alteração dos arquivos de log para encobrir seus rastros. Reduza o número de pessoas que podem manipular os arquivos de log. Autorize acesso somente a contas altamente confiáveis, como as dos administradores.
Fazer backup dos arquivos de log e os analisar regularmente
Não há porquê criar um log se os arquivos de log nunca são analisados. Os arquivos de log devem ser removidos dos servidores de produção regularmente. A freqüência de remoção depende do nível de atividade do aplicativo. O projeto deve considerar o modo como os arquivos de log serão recuperados e movidos para servidores offline para análise. Quaisquer protocolos e portas adicionais abertos no servidor Web com essa finalidade devem ser fechados de forma segura.
Diretrizes de projeto do aplicativo
Categoria Diretrizes
Validação da entrada Não confiar na entrada; considerar a validação da entrada centralizada.
Não confiar na validação do lado do cliente. Ter cuidado com questões de canonização. Restringir, rejeitar e limpar a entrada. Validar dados por tipo, tamanho, formato e intervalo.
Autenticação Dividir o site nas áreas de acesso anônimo, identificado e autenticado. Utilizar senhas de alta segurança. Oferecer suporte para senhas com validade e desativação de conta. Não armazenar credenciais (utilizar hashes unidirecionais com valores falsos). Criptografar os canais de comunicação para proteger os identificadores de autenticação.
Transmitir cookies de autenticação de formulários somente por conexões HTTPS.
Autorização Utilizar contas com a menor quantidade de privilégios. Considerar a granulação da autorização.
Aplicar a separação de privilégios. Restringir o acesso do usuário a recursos no nível do sistema.
Gerenciamento de configuração Utilizar contas com processos e serviços com a menor quantidade de privilégios. Não armazenar credenciais em texto sem formatação. Utilizar autenticação e autorização rígidas nas interfaces administrativas.
Não utilizar a LSA. Proteger o canal de comunicação para administração remota. Evitar armazenar dados confidenciais no espaço da Web.
Dados confidenciais Evitar armazenar segredos. Criptografar dados confidencias transmitidos. Proteger o canal de comunicação. Fornecer controles de acesso rígidos aos armazenamentos de dados confidenciais. Não armazenar dados confidenciais em cookies persistentes. Não transmitir dados confidenciais utilizando o protocolo HTTP–GET.
Gerenciamento de sessão Limitar a duração da sessão. Proteger o canal. Criptografar o conteúdo dos cookies de autenticação. Proteger o estado da sessão contra acesso não autorizado.
Criptografia Não desenvolver sua própria criptografia. Utilizar recursos da plataforma testados. Manter dados descriptografados próximos do algoritmo. Utilizar o algoritmo e o tamanho de chave corretos. Evitar o gerenciamento de chaves (utilizar DPAPI). Mudar as chaves periodicamente. Armazenar chaves em um local restrito.
Manipulação de parâmetros Criptografar o estado de cookies confidenciais. Não confiar nos campos que o cliente pode manipular (seqüências de caracteres de consulta, campos de formulário, cookies ou cabeçalhos HTTP). Validar todos os
valores enviados a partir do cliente.
Gerenciamento de exceções Utilizar um tratamento de exceções estruturado. Não revelar detalhes confidenciais da implementação do aplicativo. Não registrar em log dados particulares, como senhas. Considerar uma estrutura de gerenciamento de exceções centralizado.
Auditoria e log Identificar comportamento mal–intencionado. Saber como é um tráfego normal. Executar atividades de auditoria e log em todas as camadas do aplicativo. Proteger o acesso aos arquivos de log. Fazer backup dos arquivos de log e os analisar regularmente.
A segurança deve difundir–se por todos os estágios do ciclo de desenvolvimento do produto e deve ser um dos pontos principais do projeto do aplicativo. Preste atenção, especialmente, ao projeto de uma estratégia rígida de autenticação e autorização. Lembre–se também de que a maioria dos ataques no nível do aplicativo utiliza dados com entrada mal–intencionada e uma validação fraca da entrada do aplicativo. As instruções apresentadas neste módulo ajudarão você com esses e outros aspectos complicados referentes ao projeto e à criação de aplicativos seguros.
fonte:msdn,MXStudio















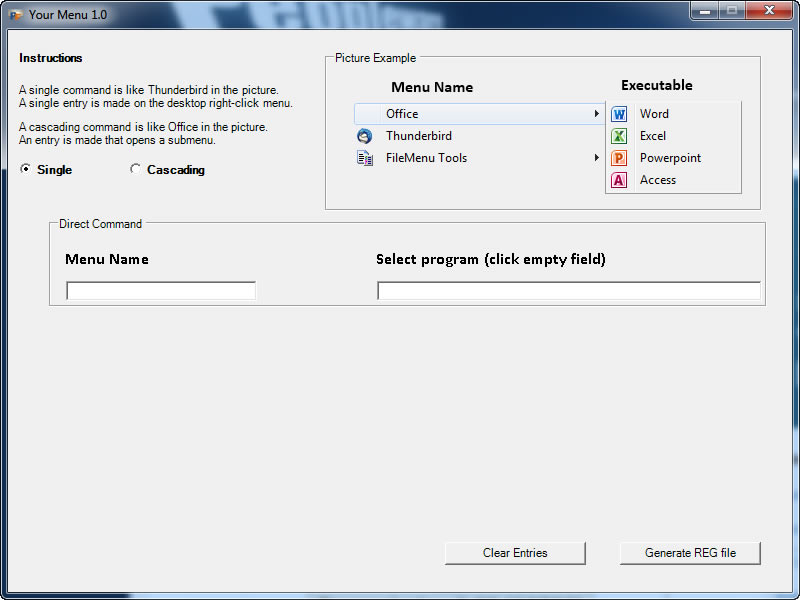
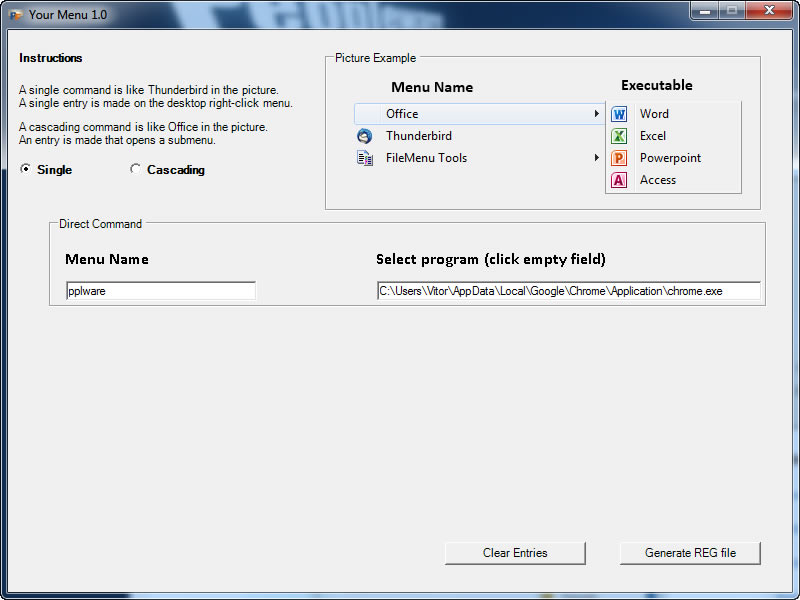


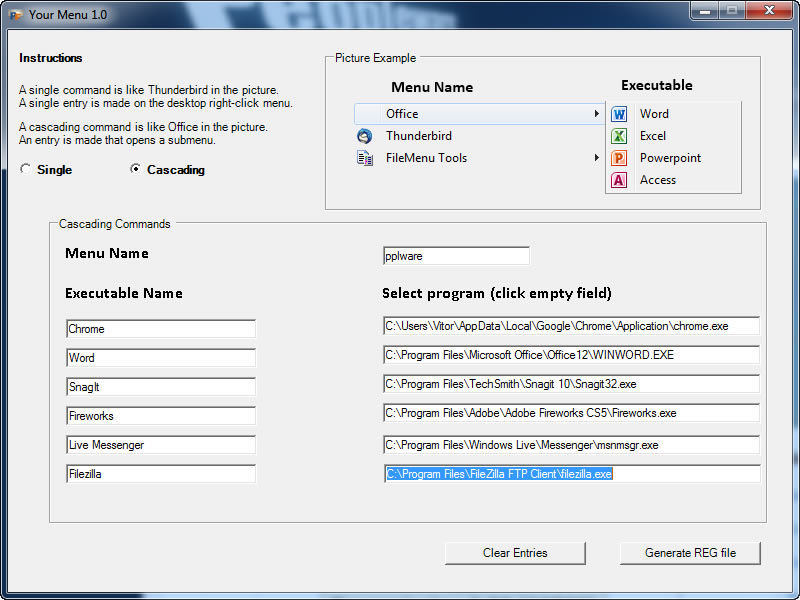
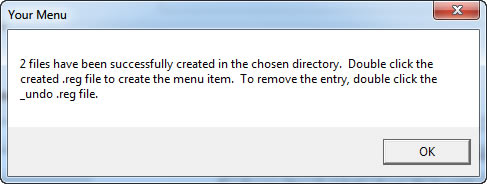
 Licença: Freeware
Licença: Freeware Sistemas Operativos: Windows 7
Sistemas Operativos: Windows 7 Download:
Download:  Homepage:
Homepage: 

























