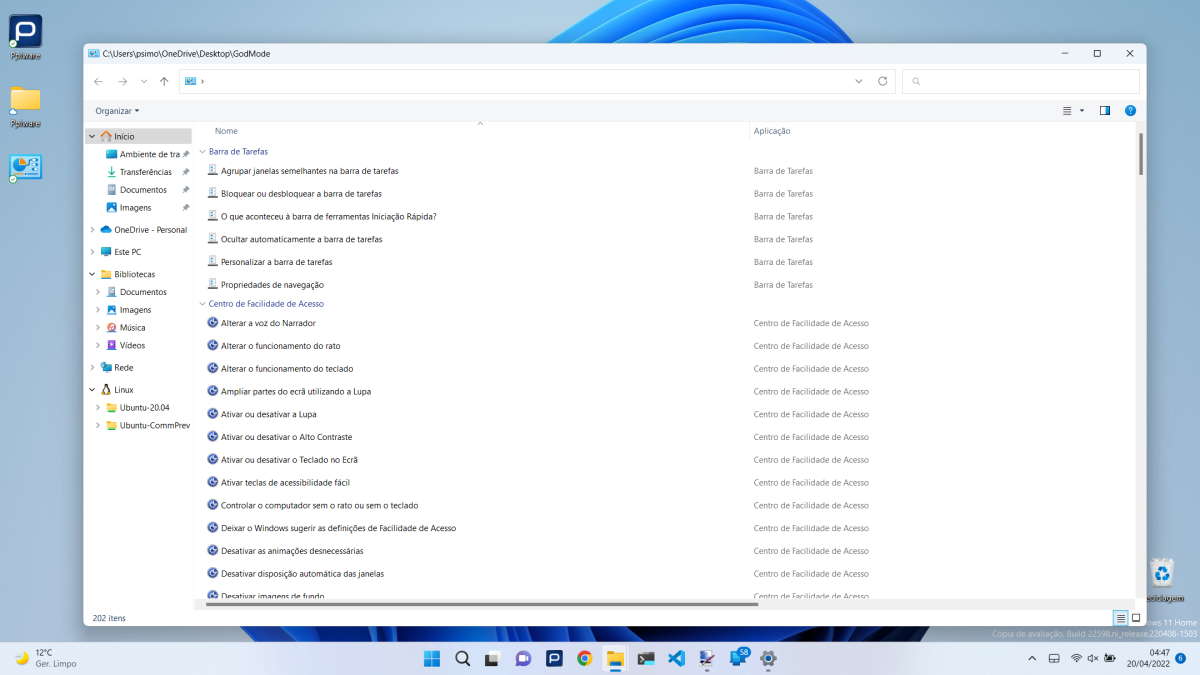
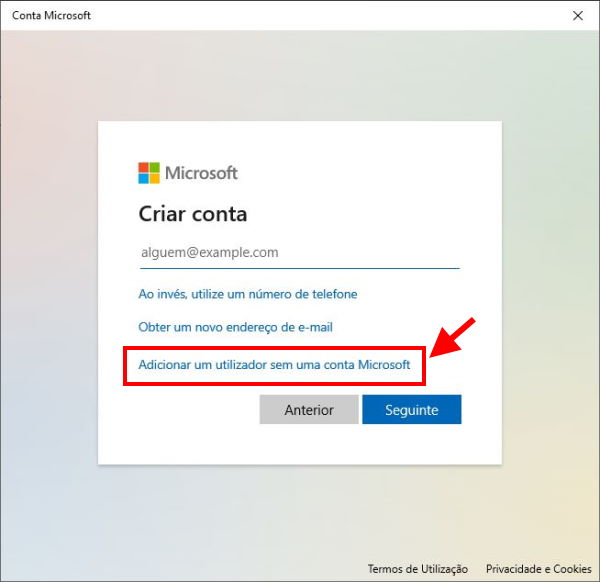
1. PhotoWorks
Começamos com o PhotoWorks, aquele que é considerado como um dos mais inteligentes editores de fotografia para PC.
Não obstante, a aplicação vem equipada com todas as ferramentas essenciais para a edição de imagens, mas tem também uma série de funções avançadas.
Inicialmente, o PhotoWorks permite aos utilizadores melhorar automaticamente as suas imagens – as edições são baseadas no género da imagem e oferecem o melhor aspecto possível.
Em segundo, existe um módulo de retoque de retratos alimentado por Inteligência Artificial (AI) e, importante, não envolve selecção manual ou aplicações de máscaras. Neste caso, apresenta um conjunto de pré-configurações com um clique e arrastamentos convenientes que proporcionam resultados surpreendentemente naturais.
Certamente que o kit de ferramentas do software também oferece:
- Alteração semi-automática do fundo,
- Processamento em grupo,
- Mais de 200 efeitos,
- Filtros HDR, e LUTs 3D,
- instrumentos para remoção de objectos estranhos,
- Entre outras funções.
Resumidamente, o PhotoWorks é um programa fácil de usar que pode ser utilizador por vários tipos de utilizadores com vários níveis de conhecimentos. Mesmo ao nível de requisitos o software em si não requer muita potência RAM.
Apesar de ser bastante rico em funcionalidades, PhotoWorks oferece apenas edição em camadas muito básicas, estando no top melhores editores de fotos e imagens para o Windows 11 em 2022.
Principais características do PhotoWorks:
Em poucos pontos, vamos mostrar o quão útil se pode considerar esta ferramenta. Então, vejamos as principais carcaterísticas:
- Auto-correcção consciente do conteúdo,
- Recurso de processamento em grupo,
- Retoque de retrato com apenas um clique,
- Ferramentas Pro para correcção de cor: Curvas, HSL,
- 200+ efeitos e filtros incorporados
- Ferramentas de escultura facial e corporal
- Suporte de mais de 450 formatos RAW
Sem dúvida, de todas as opçoes que aqui estamos a apresentar este software mostra uma grande diferença, quando comparado com os demais.
2. Luminar AI
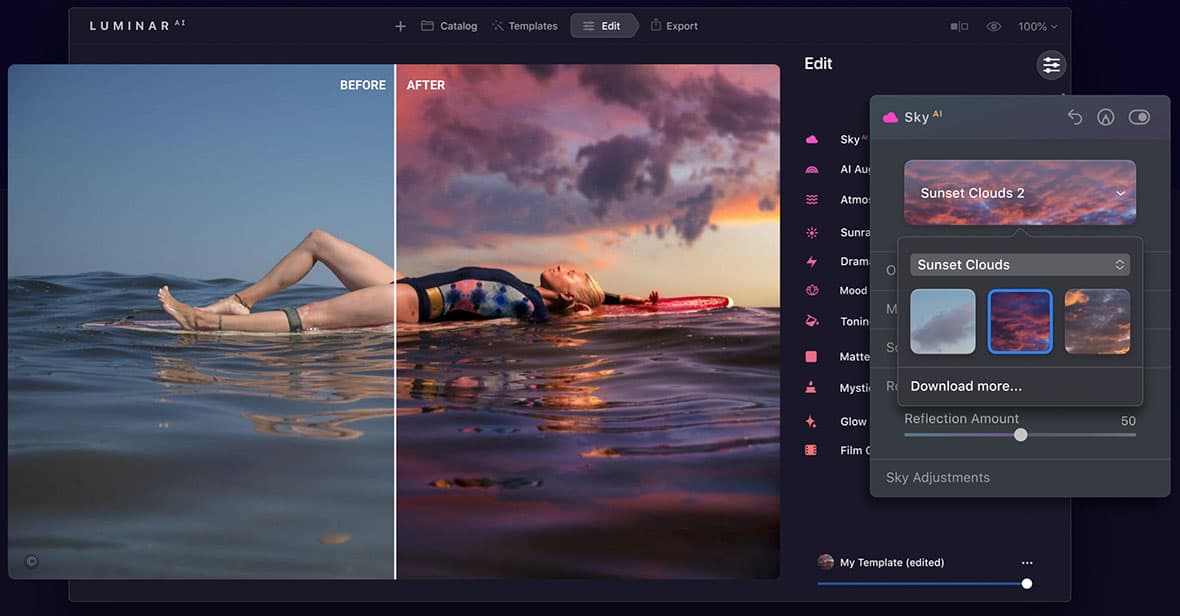
Desde já, começamos por definir o Luminar AI como sendo outro editor de fotografia inteligente para Windows 11.
Sabe aquela situação em que necessita de uma pós edição rápida? Então este software é sua cara, pois apresenta uma solução elegante de Templates.
No fundo, os Templates são nada menos que conjuntos de perfis diferentes que transformam as nossas imagens num ápice, como por exemplo:
- Alterar a imagem em termos de cor,
- Gama dinâmica e exposição,
- Ferramentas manuais de seleção de equilíbrio de cor,
- Instrumentos de corte e perspectiva, etc.
Na verdade, podemos encontrar características específicas, alimentadas por Inteligência Artificial, que podem ser bastante impressionantes, entre elas a substituição automática do céu e efeitos de nevoeiro ou névoa, etc.
De antemão, o Luminar AI apresenta-se com com ferramentas de retoque de retrato relativamente, digamos, decentes. Tem alguns sliders que lhe permitirãoaliviar e suavizar a pele, eliminar imperfeições, realçar os olhos, sobrancelhas, e lábios, e emagrecer o rosto do modelo, caso o deseje.
Contudo, importante, caso escolha este software como ferramenta certifique-se de um detalhe importante: o seu hardware tem de ser de primeira qualidade pois caso contrário, o programa não funcionará da forma desejada ou mesmo correctamente.
Principais características do Luminar AI:
- Modelos, Templates, para edição rápida e estilização,
- Efeitos da natureza realistas como nevoeiro, raios de sol, etc.
- Retoque de retratos com base em deslizadores,
- Fundo artístico com efeitos acima da média
3. ON1 Photo RAW

ON1 Photo RAW apesar do nome, não se assuste, pelo menos já!
Ao mesmo tempo que o programa pode servir como sendo um software de edição de imagem autónomo como também pode servir como um plugin do Photoshop.
Resumidamente, esta app foi pensada para se dedicar principalmente à manipulação do formato de imagem RAW, o que inclui a edição de imagem com ferramentas de topo para uma melhoria rápida e eficiente.
Por outro lado, para além de instrumentos básicos, o ON1 Photo RAW oferece características de nicho como:
- Junção panorâmica,
- Correcção de lentes,
- Retoque facial inteligente.
Logo depois, existem também ferramentas de edição de camadas e um conjunto respeitável de filtros.
Apesar de possuir um fluxo de trabalho relativamente fácil, o ON1 Photo RAW pode requer algum tempo para nos habituarmos, especialmente devido à sua interface mais complexa e por vezes confusa.
Mas, sem dúvida, a maior desvantagem deste programa que, de resto, merece toda a nossa atenção é que tem uma tendência para se arrastar um pouco.
Principais características do ON1 Photo RAW:
- Fusão do HDR e colagem (junção) panorâmica,
- Colecções de filtros, texturas, & bordos,
- Correcção da desajustes cromáticos,
- Edição de metadados,
- Pincéis personalizados
4. CyberLink PhotoDirector
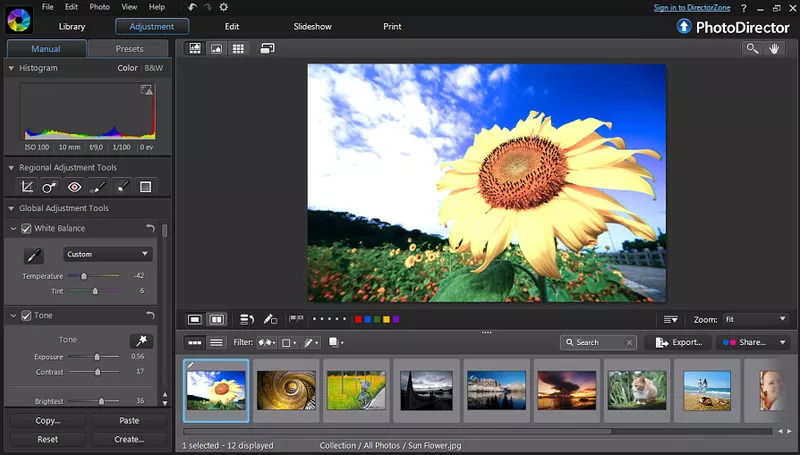
Igualmente a outros grandes nomes do mercado, o CyberLink PhotoDirector é uma aplicação fotográfica multifuncional para Windows 11 que inclui funcionalidades de catalogação e edição.
tanto quanto podemos apontar, entre as suas características mais proeminentes estão:
- A substituição via IA pelo céu,
- A remoção de objectos sensíveis ao conteúdo,
- A criação de GIF,
- Ferramenta de emagrecimento do corpo – sim, leu mesmo bem!
Embora PhotoDirector não tenha tantas ferramentas poderosas como, digamos, o Lightroom, certamente ultrapassa o produto Adobe em termos de pincéis disponíveis e outras ferramentas de pintura.
Não obstante, outra vantagem deste editor de fotografia para PC é o seu fluxo de trabalho relativamente fácil. O PhotoDirector não está, contudo, isento de certos inconvenientes. A maior delas é a exigência do software em termos de hardware.
Principais características do CyberLink PhotoDirector:
- Colagem (junção) Panorâmica,
- Apoio de tiro com fio
- Fornece acesso a imagens de stock
- Suporte à edição de/por camadas (layers)
5. ACDSee Gemstone Photo Editor
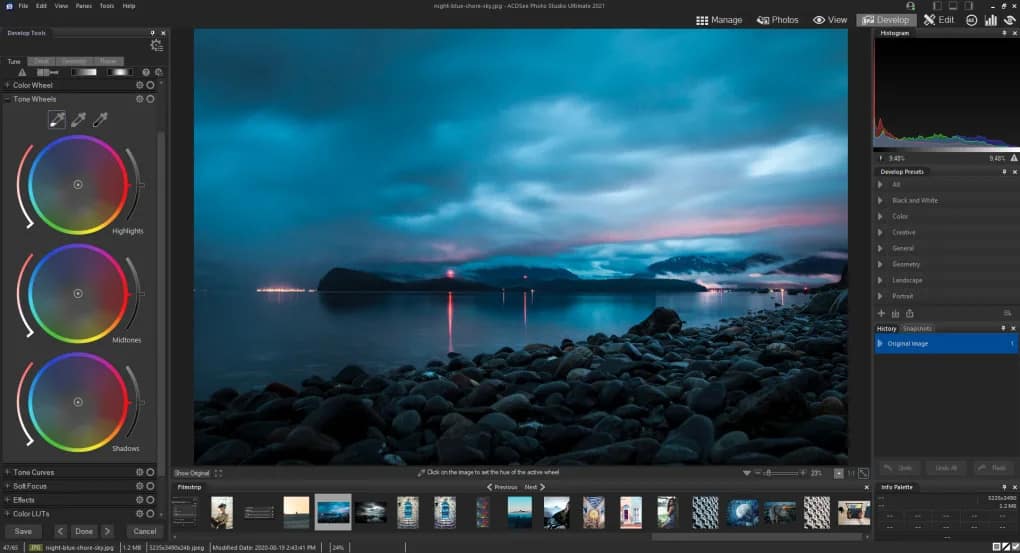
ACDSee Gemstone Photo Editor é o o topo dos topos do famoso criador de software ACDSee.
Basicamente, este software vai funcionar exclusivamente com imagens RAW, oferecendo para tal uma série de características de edição.
Logo, o seu kit de ferramentas inclui (mas não está limitado a isso) a:
- Correcção de cor e tom,
- LUTs e efeitos de cor,
- Instrumentos inteligentes de remoção de objectos,
- Funções de retoque de retratos.
No fundo, o Gemstone Photo Editor é relativamente fácil de usar e o que ajuda, e muito, é a sua própria uma interface simples. Infelizmente, este software para Windows 11 não tem um navegador de imagens para que possa folhear as suas imagens RAW.
Principais características do Gemstone Photo Editor:
- Conjunto de ferramentas de desenho gráfico,
- Edição em camadas (layers),
- Efeitos HDR e LUT pré-definidos
- Modelos pré-definidos para publicações nas redes sociais
6. Paint.NET
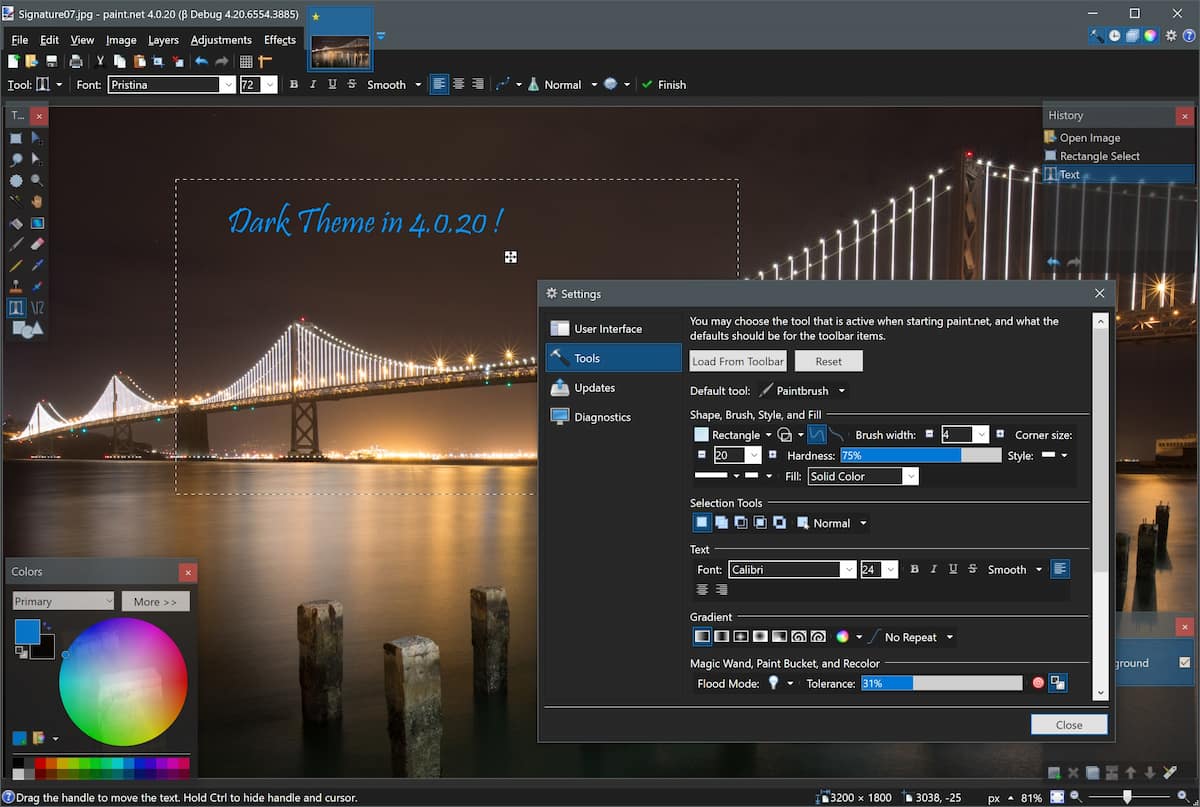
Primordialmente, não confundir o Paint do Windows 11 com o Paint.NET que é um software completamente diferente de edição de fotos.
Logo, podemos chamar a este software de edição de imagem uma versão simplificada do GIMP e Photoshop, não é brincadeira.
Para tal, a consideração pode ser apresentada graças à partilha uma série de ferramentas essenciais com os dois gigantes referidos, ficando apenas de fora todas aquelas funções mais complexas e confusos.
Ora, o Paint.NET permite a melhoria básica da fotografia, edição de camadas (layers) e também aplicação de efeitos. O conjunto de ferramentas pode ser facilmente expandido através de plug-ins gratuitos.
Ao nível da interface e acesso ao utilizador, o programa chega bastante simplificado e, em pouco tempo, é fácil de dominar.
Mas, importante, não nos devemos iludir, pois daqui não vamos encontrar uma ferramenta topo de gama. O principal objectivo do Pain.NET é a simplicidade com todos os instrumentos avançados e níveis pró propositadamente omitidos. Outra app que pode figurar nos melhores editores de fotos ou imagens para o Windows 11 em 2022.
Principais características do Paint.NET:
- Interface personalizável,
- Ferramentas baseadas em camadas e níveis,
- Kit de ferramentas expansível através de plug-ins
- Coleção decente de pincéis
7. Corel PaintShop Pro
Não conhece este software? Então o melhor é mesmo desistir de ler o restante artigo uma vez que este software é dos mais antigos e famosos que persistem no mercado da edição de imagens
Assim, o Corel PaintShop Pro é um programa de fotografia para Windows 11 que pode ser utilizado como ferramenta de catalogação e como um editor de fotografia capaz.
Na verdade, a evolução do PaintShop Pro conta com a sua IA em todos os aspectos de edição:
- Desde a correcção de cor até ao retoque de retratos
- Suporta ficheiros RAW
- Permite aos utilizadores processar imagens em grupos em termos de gama dinâmica e correcção de cor.
Importante, este editor não seria um verdadeiro produto da Corel se não dispusesse também de uma vasta gama de ferramentas de desenho vectorial. Além disso, o PaintShop Pro também traz modelos incorporados para colagens e folhetos.
Sem dúvida, este é um poderoso editor de fotografia para PC que pode rivalizar com os gigantes da indústria. Contudo, esta proeza traz um preço, uma vez que o PaintShop Pro é um programa faminto de RAM e sem um bom PC, vai ser mais complicado trabalhar com ele.
Principais características do Corel Paintshop Pro:
- Ferramentas de desenho gráfico,
- Edição raster e vectorial,
- Coleção de modelos de colagem,
- Integração das redes sociais,
- Biblioteca de pré-definições de melhoria.
8. Canva
Em resumidas palavras, o Canva é mais uma ferramenta de desenho gráfico do que um editor de fotografia adequado, embora possua algumas ferramentas para a fixação de questões fotográficas comuns.
Logo, o principal objectivo desta aplicação baseada na web é a criação de todo o tipo de materiais visuais. O Canva oferece um tremendo conjunto de modelos para anúncios, cartazes, panfletos, posts nas redes sociais, currículos, etc.
Em segundo, no que a ferramentas de edição de fotos diz respeito, estas estão na sua maioria limitadas a modificações simples e a um conjunto de filtros. O Canva é uma aplicação freemium, o que significa que, embora possa definitivamente utilizá-lo gratuitamente, as suas opções de modelos serão severamente limitadas.
Principais características do Canva:
- Milhares de modelos para materiais visuais,
- Elementos gráficos personalizáveis,
- Modo de colaboração,
- Biblioteca de imagens de stock
9. PicMonkey
Desde já, define-se o PicMonkey como um editor de fotografia online extremamente fácil de usar.
Sobretudo, foi pensado para se destinar a utilizadores casuais que necessitam de corrigir as suas imagens para os seus blogs e posts Instagram, por isso não é de esperar quaisquer ferramentas de pós-processamento hardcore.
Ainda assim, com PicMonkey, pode:
- Facilmente realizar quaisquer melhorias básicas,
- Aplicar filtros,
- Retocar retratos,
- Decorar as suas fotos com texto, clipart, e molduras.
Este software de edição de imagens infelizmente não tem qualquer recurso de processamento em grupo e requer uma ligação estável à Internet para um desempenho sem bugs.
Principais características do PicMonkey:
- Grande coleção de filtros e efeitos,
- Ferramentas de edição com base em corrediças,
- Layouts e modelos de colagens,
- Retoque eficiente de retratos.
10. Inpaint
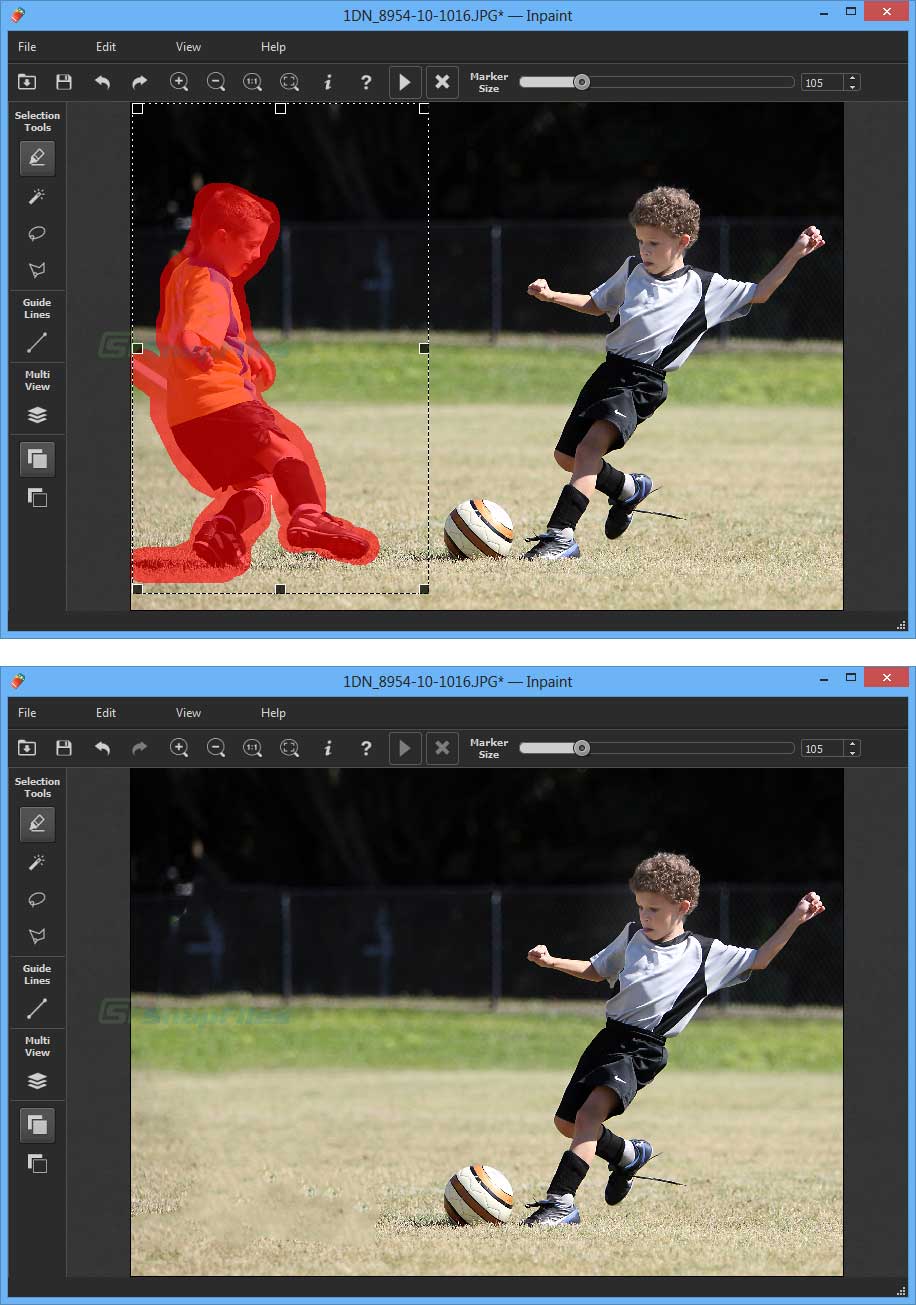
Para começar, o nome Inpaint não será do conhecimento de muitos dos leitores deste artigo.
Então, a definição melhor que podemos atribuir é tratar-se de um programa de edição de fotos para Windows 11 com um conjunto de ferramentas severamente limitado.
Ainda mais, os programadores escolheram armazenar o programa com as características mais usadas e procuradas e torná-las tão boas quanto possível (ao invés de terem um kit de ferramentas alargado onde o desempenho de cada ferramenta seria subparcial).
Seja como for, é para isto que o Inpaint é bom: remover objectos estranhos, apagar marcas de água e selos de data, e consertar “arranhões”, bolhas e vincos de fotografias antigas. Basicamente, não há características adicionais.
Principais características do Inpaint:
- Remoção de objectos sem pares,
- Resultados rápidos,
- Ferramenta para restaurar espaços em branco em panorâmicas.
11. PhotoScape

Antecipadamente, o PhotoScape é um software para PC que combina um editor fotográfico robusto, um programa de colagem fácil, e um programa de catalogação conveniente, um verdadeiro 3 em um.
Ou seja, possui todas as ferramentas de pós-processamento necessárias, juntamente com alguns instrumentos avançados de restauração de fotografias.
Ao mesmo tempo, o PhotoScape suporta ficheiros RAW e permite a edição em grupos de imagem. Existem, também, bastantes filtros e uma funcionalidade de criação de GIF. Ainda assim, o editor de imagens tem tendência para diminuir a qualidade das suas fotografias após a edição – este é um ponto absolutamente importante para todos os utilizadores.
Principais características do PhotoScape:
- Correcção fotográfica com um clique,
- Conveniente ferramenta de gestão de fotos,
- Milhares de modelos de colagem.
12. PhotoDiva
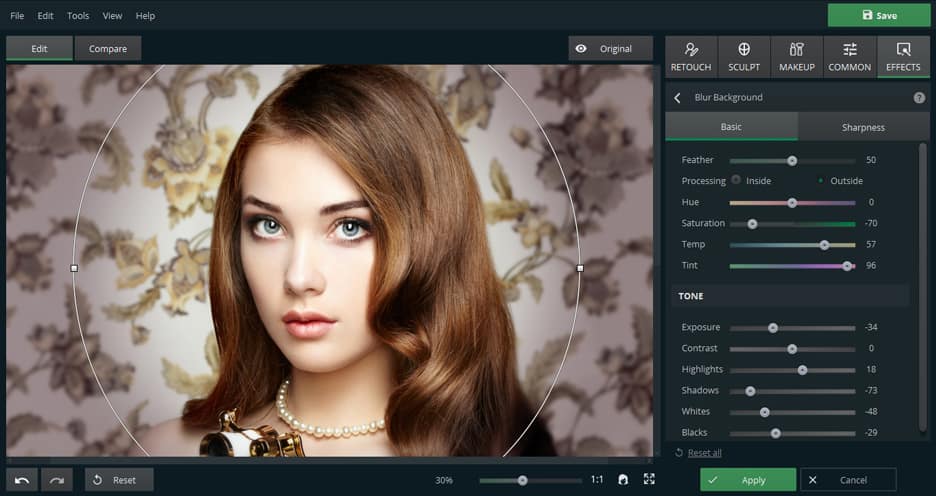
De acordo com outros software já aqui apresentados, o PhotoDiva é um software gratuito de edição de fotos para Windows 11 que se concentra principalmente no retoque de retratos.
De maneira idêntica, existem milhares de predefinições alimentadas por IA que podem retocar o rosto do modelo com apenas um clique no rato:
- Suavizar a pele,
- Branquear os dentes,
- Remover olheiras, etc.
Igualmente, estão também presentes instrumentos manuais à base de lâminas deslizantes. O PhotoDiva oferece uma ferramenta de maquilhagem virtual sofisticada, instrumentos para remoção de objectos, uma característica de escultura facial e corporal e mais de uma centena de filtros artísticos.
Por outro lado, o software está também equipado com instrumentos essenciais para melhoramento de imagem, recorte, afinação, etc.
Por último, podemos afirmar que o PhotoDiva tem uma interface simplificada e é fácil de navegar. Ainda assim, o software apresenta alguns problemas no processamento de imagens com maior dimensão, contudo para uma grande maioria dos utilizadores é perfeitamente viável.
Principais características do PhotoDiva:
- Pré-configuração automática de embelezamento,
- Ferramentas de escultura facial e corporal,
- Característica de maquilhagem virtual,
- Ferramenta de mudança fácil de fundo,
- Suporte de ficheiros RAW
13. PortraitPro
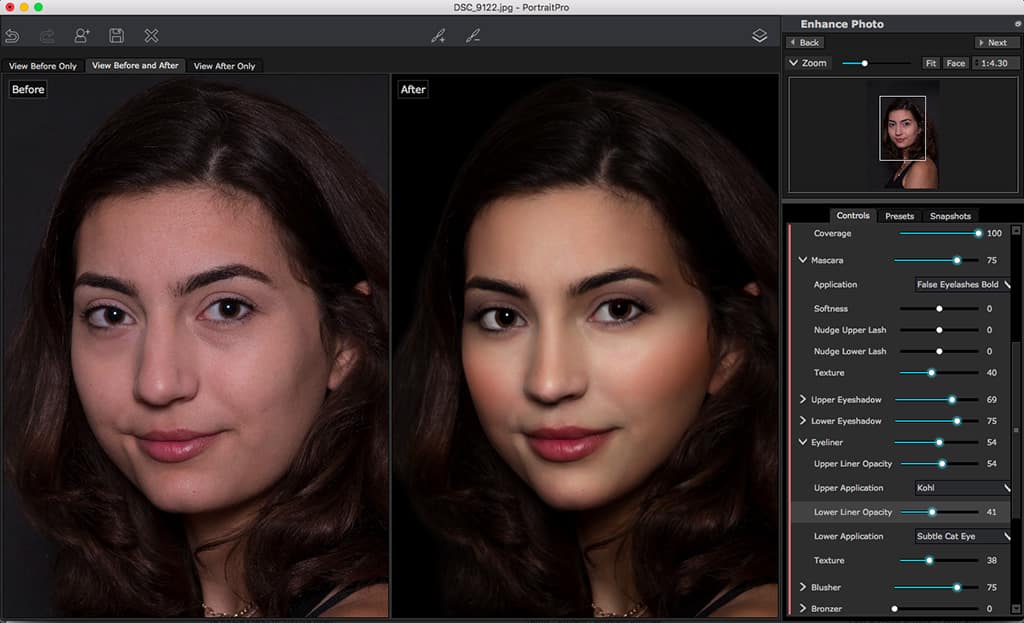
Em contrapartida ao software anterior, encontramos o PortraitPro outro software de edição de retratos que é considerado como de topo, na sua gama.
Em contrapartida, está equipado com uma IA avançada e oferece tanto ferramentas de embelezamento manual como automático.
Por outro lado, existem funcionalidades de processamento em grupo de imagens, instrumentos de remoção de objectos, e escovas de iluminação.
De maneira idêntica, o PortraitPro oferece opções como a substituição do céu alimentada por IA para tornar as suas fotografias ainda mais merecedoras de Instagram. O software é perfeito parautilizadores com poucos conhecimentos ou iniciantes, devido ao seu fluxo de trabalho intuitivo. Contudo, aconselha-se o uso dos efeitos de embelezamento com moderação, uma vez que têm a tendência de trazer resultados com um pouco de aspecto demasiado plástico.
Principais características do PortraitPro
- Suporte de formatos RAW,
- Capacidade de embelezar, mesmo fotos de perfil,
- Detecção de características faciais sem par,
- Remoção rápida do fundo
14. PhotoGlory
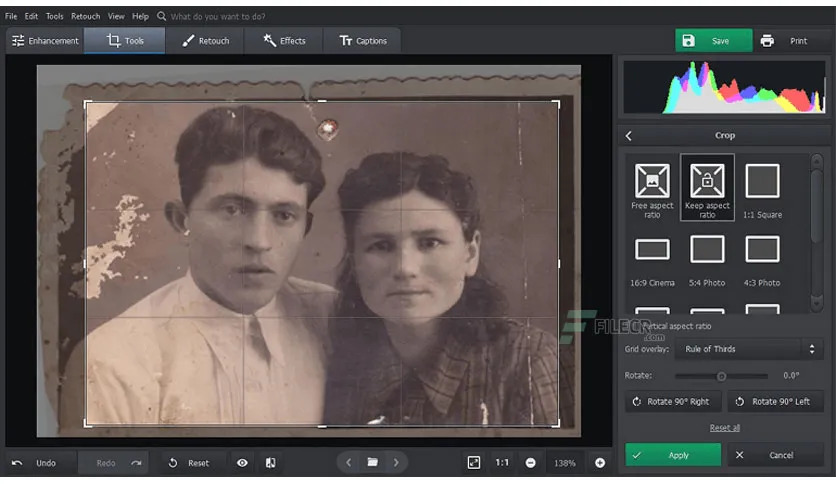
Enquanto existem editores básicos, depois, há o PhotoGlory que se define como um editor de fotografia para Windows 11 que tem um conjunto de ferramentas estritamente limitado, mas, neste caso, é por uma boa causa.
No fundo, esta aplicação foi desenvolvido especificamente para o restauro de fotos antigas. Devidamente equipado com uma IA bem pensada, o software permite o restauro automático e coloração de imagens antigas.
Segudamente, existem também ferramentas manuais para remoção de defeitos, bem como uma série de instrumentos de correcção de cor que o ajudarão a aumentar as cores desbotadas.
Ao mesmo tempo, e apesar de ser avançado nas suas características, o PhotoGlory é bastante fácil de usar e faz bem o seu trabalho, mesmo que ocasionalmente possa deixar o utilizador pendurado, também conhecido como crashado.
Principais características do PhotoGlory
- Coloração automática e manual,
- Restauro de imagens antigas com um clique,
- Coloração de imagens em conjuntos de imagens,
- Curvas e LUTs 3D para correcção de cor,
- Mais de 150 efeitos de estilo: vintage, tonificação, etc.
15. AKVIS Retoucher

Restauro de fotografias antigas? Então o AKVIS Retoucher é outro editor de imagens que oferece das melhores ferramentas para o efeito sobre a recuperação de fotografias antigas.
Assim, todas as correcções são executadas automaticamente – basta escolher o modo de processamento correcto. Por outro lado, o software também permite melhorar as imagens ditas «normais» – modernas – corrigindo-as por cor, eliminando objectos aleatórios, e melhorando a sua composição.
Sob o mesmo ponto de vista, na verdade, não há muito mais que o AKVIS Retoucher possa fazer, pelo que a sua relação custo-benefício é questionável.
Principais características do AKVIS Retoucher
- Remoção automática de defeitos,
- Fácil ocultação de objectos estranhos,
- Ferramentas de correcção de cor .