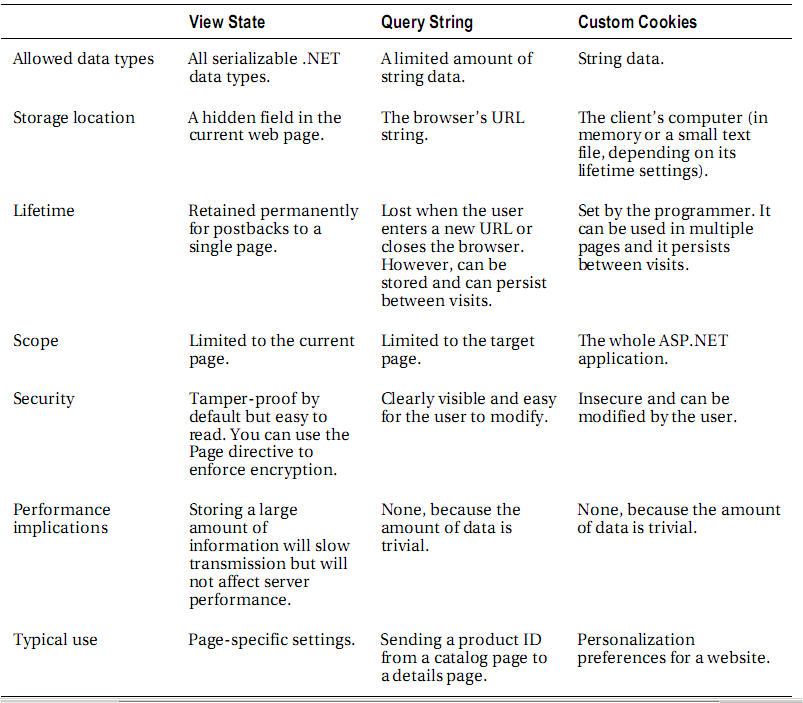
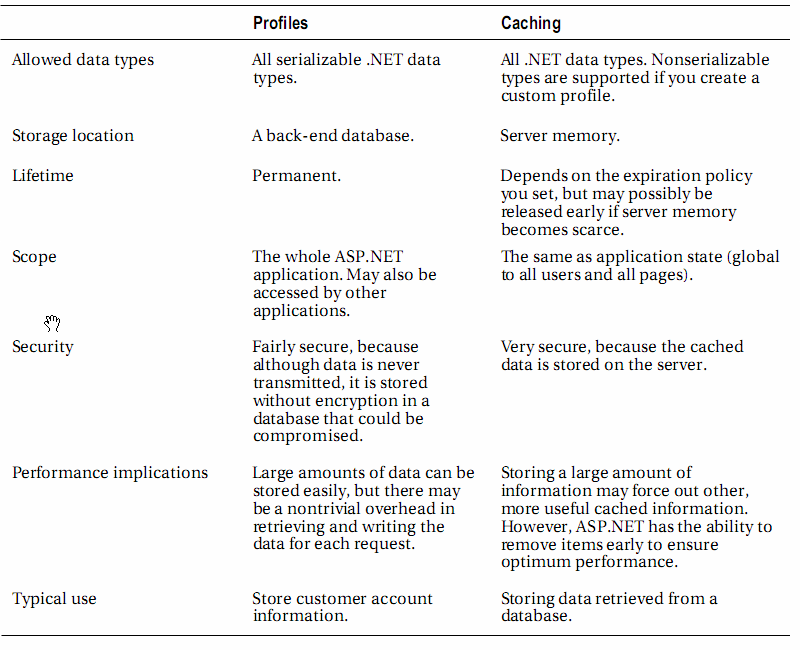
Dica: Recuperar contactos do Gmail
Criado por Pedro Simões em 21 de Dezembro de 2010 | 12 comentários
Há uns dias atrás recebi uma chamada urgente de um amigo que em desespero me tentava dizer que todos os seus contactos, que estavam alojados no Gmail tinham desaparecido de forma estranha. Depois de o conseguir acalmar lá consegui perceber que este infortúnio tinha sido obra de uma tentativa de sincronização com um qualquer serviço web de sincronismo e partilha de contactos.
O seu desespero era tal que ele já ponderava telefonar para os serviços da Google para que lhe fizessem o restauro de um qualquer backup antigo. Estava disposto a pagar por isso e muito. Eram “apenas” dois anos de contactos que tinham voado pela janela. Estava muito em jogo e eu, felizmente, tinha a solução!! Tudo passaria por uma função que a Google tinha lançado há poucos dias e que tinha sido pensada para estas situações. A recuperação de contactos chegou ao Google Contacts.

O processo de recuperação de contactos é uma das mais recentes novidades que a Google lançou para o seu serviço de email. Conseguem com ela recuperar para uma data anterior a vossa lista de contactos. Infelizmente, e por agora, todos os contactos que adicionaram depois da data da recuperação serão perdidos, mas nada que um simples backup não resolva. Pode ser que a Google num futuro próximo considere a hipótese de fundir os contactos existentes com os que forem recuperados.
Mas voltando ao problema do meu amigo e à forma como o conseguimos resolver… Tudo passa pela interface do Gmail. Acedam à vossa conta de Gamil e ai dentro escolham o acesso aos vossos contactos.
Na barra superior, mesmo junto à vossa lista de contactos vão achar um botão com o texto Mais acções. Escolham-no e vão ver disponível um conjunto de opções. Nelas estará a que vos interessa,Restaurar contactos.

Depois de seleccionarem essa opção será mostrada uma caixa onde podem escolher qual a data para que pretendem fazer a recuperação dos vossos contactos. As hipóteses são várias, desde os últimos 10 minutos até ao máximo de 30 dias. Este é o limite de dias que a Google guarda os vossos contactos.
Escolham então a data pretendida, dentro das possibilidades oferecidas e carreguem no botãoRestaurar.

No final do processo será mostrada uma mensagem a indicar que os vossos contactos foram recuperados para a data pretendida. Verifiquem se os contactos que queriam estão já lá e se não ficarem satisfeitos repitam o processo até que consigam recuperar os vossos contactos.

Espero que esta pequena dica e este novo serviço da Google vos seja tão útil como foi ao meu amigo. No final ficou bastante satisfeito pois todos os seus contactos foram facilmente recuperáveis e nenhum se perdeu, ao contrário do que ele estava à espera.
Nunca são vezes de mais todas as que vos indicamos, mas é importante fazerem com bastante regularidade um backup regular dos vossos dados importantes, mesmo os que estão alojados na Internet e, supostamente, protegidos contra todos os tipos de falhas e problemas.
Fica o alerta e a explicação de como fazerem o restauro dos vossos contactos no serviço de email da Google!
![]() Homepage: Gmail
Homepage: Gmail ![]() Homepage: Google Contacts
Homepage: Google Contacts